Martin Dudek
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
Sure feel free to ask questions i will reply whenever i find time. I probably won't feel like digging into all the details of this 6 month old project but sure i can help you with more fundamental questions about the Mojo aspect of it if you stuck. To understand llm.c , you said you have a buddy who is deeply involved in it, so you better ask him.
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
I checked it out and came to the conclusion, you didn't read
https://docs.modular.com/magic/
😉
It's 'magic run .. ' not 'mojo run ... ' or 'magic shell' first and then you are in an 'env' in which you can run the 'mojo' command.
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
Great . Curious what you make out of it. I don't rule out myself that I might pick it up at one point again - after all it's my mojo one hit wonder 😀 - but as of now I don't really see any interesting way to improve it without diverting significantly from the idea of the original llm.c .. please drop me a line when you publish something
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
There are plenty of ports, did you see https://github.com/karpathy/llm.c?tab=readme-ov-file#notable-forks
Sure feel free to fork it and do what you want, it is there for the community to play around with. Following Andrej, I published it under the MIT license, that should also formally give you all the freedom you want.
After the first implementation, i did not really touch it much anymore, except to make sure it runs with new stable Mojo versions. I am sure the code could be refined, but for me its basically a proof of concept project.
If you want to port to another language, i would highly recommend to just go with the original C version ... if you are a Rust guy, that port looks very solid to me and its fast too. I havent looked at any of the other ports.
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
Porting from C to Mojo is actually - at least for me - much easier than porting from Python.
When Karpathy published llm.c i had time to make this port and he kindly early on added it to the notable ports section on the llm.c github page. He seems to be a really nice guy and I am big fan of the educational stuff he puts on youtube, so it was a pleasure for me to do this project.
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
Thanks @Robert - this is a 6 month old project, and actually mentioned on the Mojo language intro page https://www.modular.com/mojo , next to much cooler projects like Endia, Basalt and LightbugHTTP . Well the blessing of the name Andrej Karpathy got it there i guess 😂
18 replies
MModular
•Created by Jack Clayton on 5/11/2024 in #community-showcase
llm.mojo: GPT2 fine-tuning and inference in a single Mojo file
Just updated it to 24.6 . A bit of a ride as it was on 24.4 but mostly straight forward
DTypePointer -> UnsafePointer transitions and adding/changing of various imports.
I have no further plans with this project but nice to have at least updated to the latest Mojo version ...18 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #community-showcase
Mojo added to SpeedTests repo on github
it seems the github repo owner is very open for further PRs even so maybe good not to bombard him too frequently with PRs 😉
16 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #community-showcase
Mojo added to SpeedTests repo on github

16 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #community-showcase
Mojo added to SpeedTests repo on github
Some insightful comments by @Owen Hilyard and @Martin Vuyk on various ways how this simple task can be implemented appeared on github https://github.com/jabbalaci/SpeedTests/pull/63 :mojo:
16 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #community-showcase
Mojo added to SpeedTests repo on github
There are only five numbers printed by the program, so this change likely won't have a noticeable impact on performance. When I run the program locally, it seems that the current nightly version is actually performing a bit slower for some reason. Let's wait for the next stable version to see if there’s a noticeable performance improvement. If there is, I'll request the GitHub repository owner to rerun the benchmark with the latest version.
16 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #questions
List of references in Mojo
this looks great, thanks a lot
8 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #questions
List of references in Mojo
It would be great if someone could post how to implement this example with References (and/or Arc) - never used them so not sure how to do it
8 replies
MModular
•Created by Martin Dudek on 10/18/2024 in #questions
List of references in Mojo
This will copy the lists as far as i see:
8 replies
MModular
•Created by Sören on 7/29/2024 in #questions
Any way to work around that capturing closures cannot be materialized as runtime values?
thx
8 replies
MModular
•Created by Martin Dudek on 10/11/2024 in #community-showcase
Mojo dictionary benchmarks
No, I don't have anything to say about it — the folks actively engaged in the discussion here would be the best ones to comment on dictionary performance and what to expect in the future ...
69 replies
MModular
•Created by Sören on 7/29/2024 in #questions
Any way to work around that capturing closures cannot be materialized as runtime values?
Did you find a workaround for that? Facing the same limitation here. Thx
8 replies
MModular
•Created by Martin Dudek on 10/11/2024 in #community-showcase
Mojo dictionary benchmarks
wonderful to hear that all this knowledge is flowing into stdlib dict, thanks to everyone involved in this 🙏 :mojo:
69 replies
MModular
•Created by Martin Dudek on 10/11/2024 in #community-showcase
Mojo dictionary benchmarks
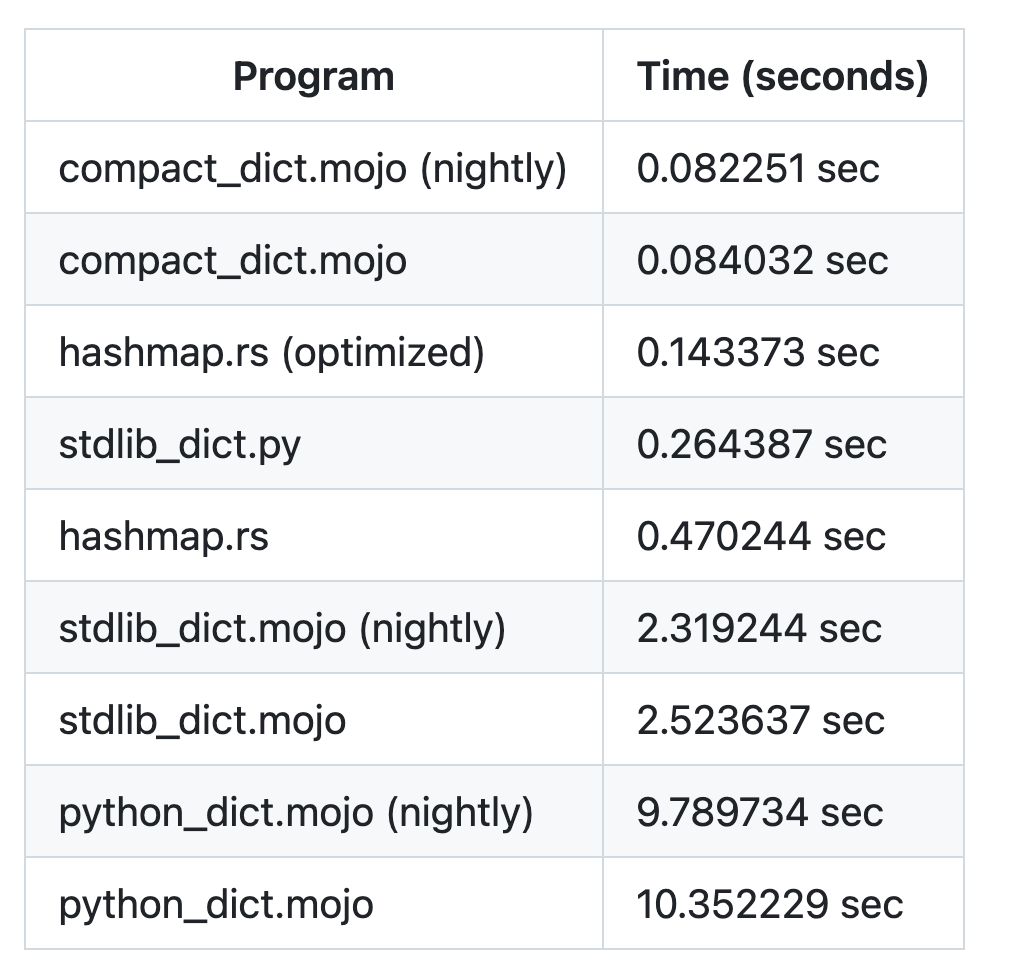
69 replies
MModular
•Created by Martin Dudek on 10/11/2024 in #community-showcase
Mojo dictionary benchmarks
just played around with creating the String keys outside the benchmark and as @Maxim already assumed, it changes the picture - i will update the repo later today
69 replies