Mojo dictionary benchmarks
I've published a GitHub repository intended as a baseline for comparing the performance of various dictionary implementations in Mojo, with Python and Rust implementations as additional references. You can find it here: https://github.com/dorjeduck/mojo-dictionary-benchmarks.
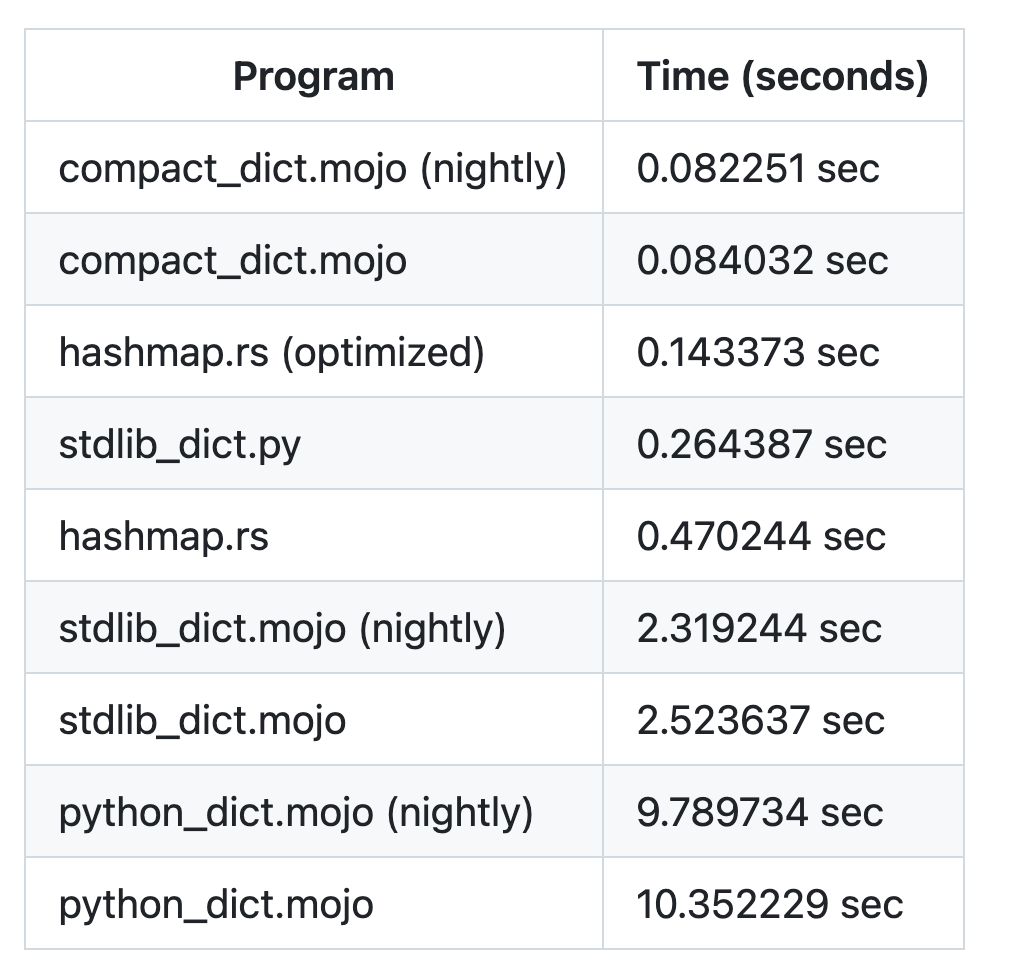
My hope for this is to serve as a foundation for community discussions on improving Mojo's dictionary performance , especially since current results show Python and Rust implementations with significant performance advantages. The best Mojo approach I am aware of so far is @Maxim's compact-dict: https://github.com/mzaks/compact-dict
My current focus on dictionaries is driven by the desire to improve the performance of my tokenizer implementation in https://github.com/dorjeduck/minbpe.mojo.
All comments and contributions are most welcome. I quickly put this together to provide a starting point for discussions. Thanks! 🙏
GitHub
GitHub - mzaks/compact-dict: A fast and compact Dict implementation...
A fast and compact Dict implementation in Mojo 🔥. Contribute to mzaks/compact-dict development by creating an account on GitHub.

45 Replies
The Rust benchmark is slightly different as the dict type is
dic: HashMap<usize, usize> hashing a usize is much cheaper than hashing a string.
Generally if we want to benchmark a Dict where key is string and value is int, we should decouple the creation of keys from the actual dictionary operations. In my experiments Compact dict was faster than Python stdlib dict, so my suspicion is that the usage of str(i*2) might lead to a slow down. It woudl be nice if the keys would be generated outside of the benchmark, say by creating a List[String] and the references are used as keys.
One more thing regarding CompactDict, there is an upsert method to mutate or add a value for key, this should be a bit faster as it translates to only one keys lookup (hashing of the key), but one could argue that it makes the benchmark unfair as other dicts do not provide such method.
Sorry if I am too direct in the messages. I really like the idea of the benchmark, great work!thanks @Maxim i am more than happy to accept any pull request if you have the time to improve this repo - as said i just put it quickly together as starting point.
I am a bit behind on multiple things, but I will try to contribute to this repo!
I think it's also probably reasonable to give Rust
-C target-cpu=native, since Mojo is doing the same. Ideally, we should also compare with a standard hash algorithm, since the default Rust one is quite a bit slower than ahash.
@Maxim Did you want to take a pass at mojo ahash using llvm intrinsics or should I?@Owen Hilyard very welcome to make a pull request for that or i do it if you prefer
I'll do it because I want to make some modifications to the benchmark script to make it more consistent.
FIFO scheduling is great for benchmarking because you remove scheduler overhead.
very happy for all contributions as i am not an expert on these matters at all , just saw a need to look into dictionary performance.
It's also important to know that the "pop in order" requirement from python means a mojo dict will always be slower because it's a hash table + extra stuff.
Ideally, we want to break out the raw hash table so people can use that.
I was thinking the same thing. I think a lot of time is spent on alloc
I think they changed the default hash algorithm to ahash recently? Or I’m hallucinating
Rust targets x86-64-v1 by default, which is an AMD k8, and which doesn't even have POPCNT or 128 bit atomics.
Mojo defaults to whatever CPU you have, which for me is x86-64-v4 + some more stuff, which has AVX-512.
Thats a MASSIVE capability difference.
If they did, I haven't seen it, and python would still be using what is probably a less secure hash.
Also, I have an implementation of the x86 AES intrinsics for std. I need to spend some more time with ahash to figure out where I can safely make use of 4x wider instructions. Code-gen is very close to perfect for larger spans of known size, so I'll do some benchmarking to find the performance cliff so I can generate unrolled versions of the processing loop.
@Maxim What are your thoughts on having a fixed-width
write in the Hasher trait (probably both SIMD and UnsafePointer with a compile-time known size)? I know a lot of cases where the a key can be reliably constrained to 256 or 512 bytes, which translate to 4 and 8 instructions respectively with avx512. A SmallKeyDict with keys that are a maximum of N bytes could do wonders for the codegen here.I love it 😄
Please do. If you have the time. I have two PR streams in std lib in flight, One stream is hash related, the over is Unicode upper/lower case related. And I still wanted to write a proposal for code point / grapheme cluster indexing and small string optimizations based on my experiments with Crazy string. And I have to present at dotAI next week 😅. So any help is greatly appreciated.
just played around with creating the String keys outside the benchmark and as @Maxim already assumed, it changes the picture - i will update the repo later today
Updated the progs as suggested by @Maxim (key generation outside the benchmark) - wow, compact-dict rocks :mojo:
Maybe I am missing something but, why not just change the stdlib Dict code to match the compact dict ones? Is there any caveat?
I think the plan is indeed to do (some version of) that. It's just we want to get the benchmarking infrastructure ready first.
About the AHash algorithm, I think we are almost there, as recently this PR from @Maxim was merged: https://github.com/modularml/mojo/pull/3615. I've just trying the new hash algorithm on Dicts, and the speed-up it's x2 or even x2.5 in some simple benchmarks, see https://github.com/mzaks/mojo/pull/1
I have an open PR to make that even faster: https://github.com/modularml/mojo/pull/3652
wonderful to hear that all this knowledge is flowing into stdlib dict, thanks to everyone involved in this 🙏 :mojo:
It's important to note that Maxim implemented the fallback algorithm, not the real one. The fallback is good, but the real one backed by hardware AES instructions is quite a bit faster. I'm still working on implementing all the plumbing in std to enable it, but the speedup is generally proportional to the vector width of the system plus some more based on how efficient the fallback instructions were.
One area went from ~26 cycles to 3 cycles on Zen 5.
Should be easy (can be quite tedious though)
It is quite tedious.
Does anyone know if there are any Mojicians who are reasonably qualified cryptographers? I can roll my own software AES fallback, but if std is going to have an AES implementation then it probably should be a good one.
I mean you could get the implementation on supported platform in first and leave everything else
constrainted[False]That is what is currently set up
Don't hand roll your fallback. Blow up in the users face at compile time is safer
The newest processor from intel that DOESN'T support this is the broadwell pentiums/celerons (2014). For AMD pre-bulldozer doesn't have it.
ARM is where the fallback is more likely due to a lot of CPUs not implementing the cryptographic extensions.
Apple is frustratingly vague about whether apple silicon has FEAT_AES.
Then just start with assuming that they don't
I think you will need to add a bunch of functions to
sys.info. We can get those in firstApple Developer Documentation
Determining Instruction Set Characteristics | Apple Developer Docum...
Interrogate the system for details about the instruction set.
hw.optional.arm.FEAT_AESMy point is, you don't have to provide a complete solution all at once, it's more difficult to review
That's true.
This is already going to be a fairly big PR since I made x86 vector width agnostic.
I can imagine
It's not that bad, only 95 lines for the x86 implementation, but that was accomplished with rather dense metaprogramming I should probably comment more.
You could make a draft PR first and let's figure out what's the best way to get that in
I'll do that once I have better comments. Some parts of this deserve better explanation:
The copy loop is only because
pop.insert was doing weird things on Zen 5, using 256 bit stores.(width // instruction_width) * instruction_width use _align_downI may also get some grief for making ARM go up to the level of x86 by chaining 2 intrinsics to do a full round of AES.
Wow, that's very useful.
We should probably have a lint for "manual align down", since a lot of people used to writing SIMD will write what I did.
And I'd really hope you used shorter variable names. 🙃
I'd rather have longer variable names to make it vaguely self-documenting (yes I will still add comments). I'll shrink things if I run into the 80 character limit too often. I also want to bring up moving to 88 characters at some point because that cuts down on the number of lines which need to wrap a lot. Those extra 8 characters dropped 5k lines from a ~100kloc python codebase I worked on.
I'm a believer that mathy code should look like math. Plus I'm a functional programmer, so having "non-informative" var names is a feature. 🙃
I'll shrink things if I run into the 80 character limit too often.This 100%. https://github.com/modularml/mojo/issues/3637
I've +1ed the PR and added reasoning from black to increase the line length.
I tend to move further away from math as what I am doing becomes more complex unless I am implementing a formula. I write a decent amount of low-level code, and I have a strong preference for
mmio_nic_cmd_queue_doorbell_register over reg because you already have enough stuff going on in your head trying to keep the state of the driver as you are manipulating it without needing to track the meaning of variables. This is especially true in drivers which often have lots of magic constants.I also want to bring up moving to 88 characters at some pointYes plz @Owen Hilyard. The frequent spilling of function signatures over multiple lines is such an eyesore!
You’re going to hate my next PR
Doing math in the type system has some “fun” consequences in Mojo.
@Martin Dudek any interest in sharing this work during our community meeting/showcase on October 21st?
No, I don't have anything to say about it — the folks actively engaged in the discussion here would be the best ones to comment on dictionary performance and what to expect in the future ...
Sounds good