assangex
PDProgram Dream
•Created by assangex on 6/8/2024 in #🔨┃dev-logs
KMNIST
I made a testing script to put the parsed and flattened arrays into a json file, and it worked!
...i think
import numpy as np
import json
import random
from mnist import MNIST
import idx2numpy
import matplotlib.pyplot as plt
mndata = MNIST('samples')
def test_parse():
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
with open('KMNIST-FILETEST-Train.json', 'w') as f:
json.dump(train_arr.tolist(), f, indent=4)
with open('KMNIST-FILETEST-Test.json', 'w') as f:
json.dump(test_arr.tolist(), f, indent=4)
print("Parsing Complete")
test_parse()
import numpy as np
import json
import random
from mnist import MNIST
import idx2numpy
import matplotlib.pyplot as plt
mndata = MNIST('samples')
def test_parse():
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
with open('KMNIST-FILETEST-Train.json', 'w') as f:
json.dump(train_arr.tolist(), f, indent=4)
with open('KMNIST-FILETEST-Test.json', 'w') as f:
json.dump(test_arr.tolist(), f, indent=4)
print("Parsing Complete")
test_parse()
7 replies
PDProgram Dream
•Created by assangex on 6/8/2024 in #🔨┃dev-logs
KMNIST
'''
This piece of the code is what really flattens the dataset
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
'''
'''
This piece of the code is what really flattens the dataset
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
'''
7 replies
PDProgram Dream
•Created by assangex on 6/8/2024 in #🔨┃dev-logs
KMNIST
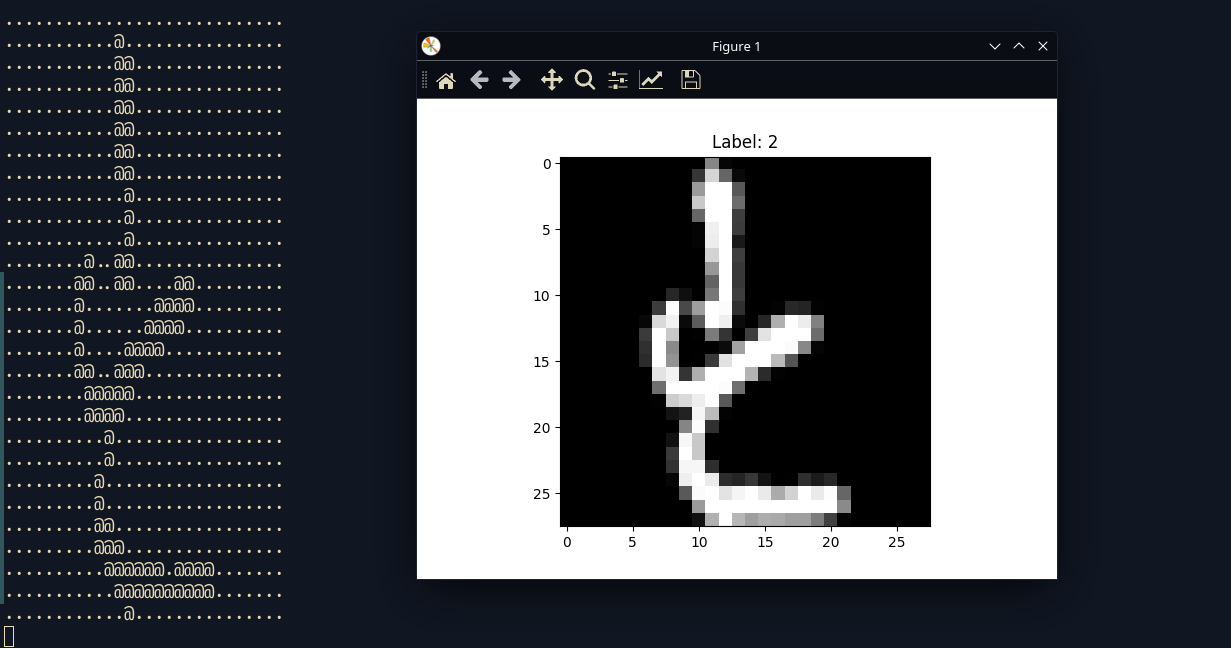
This script pretty much grabs a random label from the dataset, parses it, and sends it back to you with a ascii version of it as well as a matplotlib version of it.
def parse():
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
def randoImage(arr, labels, filename):
index = random.randrange(len(arr))
data = {
'image': arr[index].tolist(),
'label': labels[index]
}
with open(filename, 'w') as f:
json.dump(data, f, indent=4)
#save images
randoImage(train_arr, train_labels, 'KMNIST-Train.json')
randoImage(test_arr, test_labels, 'KMNIST-Test.json')
#Display random images from training dataset
index = random.randrange(len(train_arr))
print(mndata.display(train_images[index]))
image = np.array(train_images[index]) / 255.0
label = np.array(train_labels[index])
with open('image.json', 'w') as f:
json.dump(image.tolist(), f, indent=4)
with open('label.json', 'w') as f:
json.dump(label.tolist(), f, indent=4)
#matplotlib
plt.imshow(image.reshape(28, 28), cmap='gray')
plt.title(f'Label: {label}')
plt.show()
return image, label
parse()
def parse():
train_file = 'samples/train-images-idx3-ubyte'
test_file = 'samples/t10k-images-idx3-ubyte'
test_images, test_labels = mndata.load_testing()
train_images, train_labels = mndata.load_training()
train_arr = idx2numpy.convert_from_file(train_file) / 255.0
test_arr = idx2numpy.convert_from_file(test_file) / 255.0
train_arr = train_arr.flatten().reshape(-1, 28 * 28)
test_arr = test_arr.flatten().reshape(-1, 28 * 28)
def randoImage(arr, labels, filename):
index = random.randrange(len(arr))
data = {
'image': arr[index].tolist(),
'label': labels[index]
}
with open(filename, 'w') as f:
json.dump(data, f, indent=4)
#save images
randoImage(train_arr, train_labels, 'KMNIST-Train.json')
randoImage(test_arr, test_labels, 'KMNIST-Test.json')
#Display random images from training dataset
index = random.randrange(len(train_arr))
print(mndata.display(train_images[index]))
image = np.array(train_images[index]) / 255.0
label = np.array(train_labels[index])
with open('image.json', 'w') as f:
json.dump(image.tolist(), f, indent=4)
with open('label.json', 'w') as f:
json.dump(label.tolist(), f, indent=4)
#matplotlib
plt.imshow(image.reshape(28, 28), cmap='gray')
plt.title(f'Label: {label}')
plt.show()
return image, label
parse()
7 replies