KMNIST
Similar to @earth's penguin EMNIST project, I am developing a CNN (Conventional Neural Network) in python to parse a KMNIST dataset.
A quick summary of what this dataset consists of:
60,000 training and 10,000 testing examples of handwritten Kuzushiji Hiragana characters (Cursive Japanese Characters).
Do I know japanese? No
Is it a cool AI project? Yes
4 Replies
This script pretty much grabs a random label from the dataset, parses it, and sends it back to you with a ascii version of it as well as a matplotlib version of it.
I made a testing script to put the parsed and flattened arrays into a json file, and it worked!
...i think
So it ended up creating the files and for a split second i was was able to see floats :D
but because of how data there there was per file crashed :(
output:
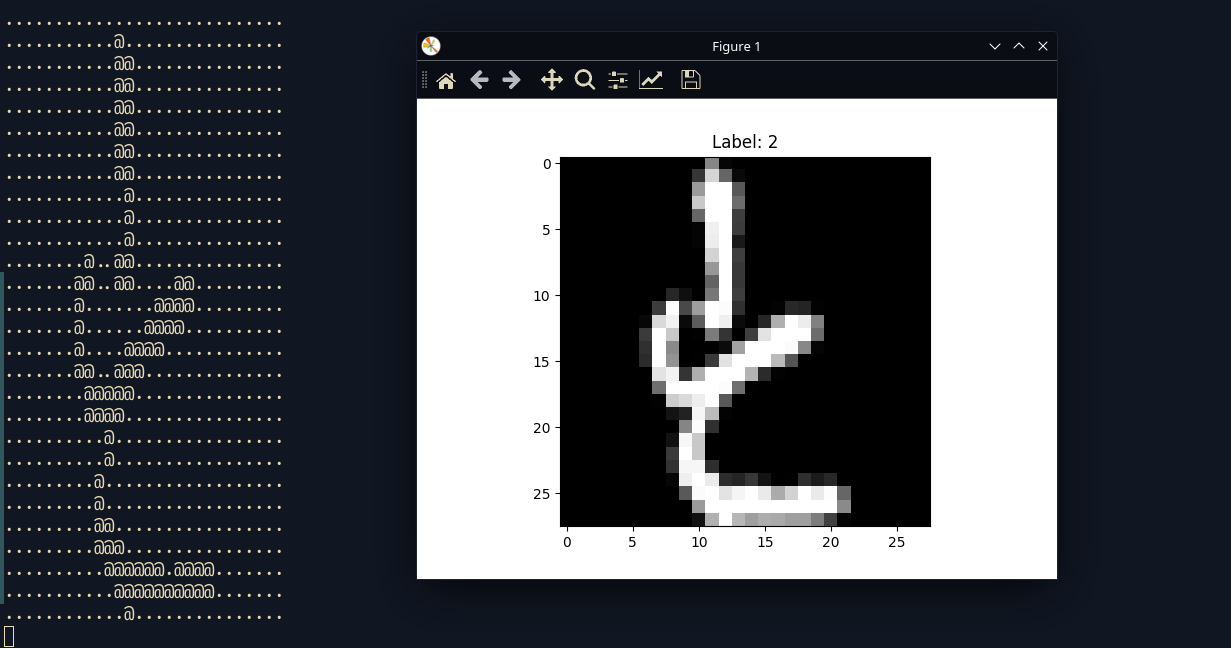
If you don't know japanese how do you verify if it's working correctly