Advice for pooling DB connections with serverless
I have a great, working web application which uses SvelteKit, DrizzleORM, a PostgreSQL database running on Amazon RDS. It is hosted on Netlify, which means that the “backend” consists of one big serverless function (sveltekit-render) which handles all the SSR stuff that SvelteKit provides but also, crucially, makes a bunch of queries to the PostgreSQL database. I have a sort of custom-built HTTP REST API which is part of the same SvelteKit application.
I don’t have to worry about huge traffic volumes, but when we got a few hundred people to connect at once, the whole thing came crashing down because the DB hit its connection limit almost immediately (100+ connections).
I think that the issue is that Netlify spins up as many instances of the “sveltekit-render” function as it thinks is necessary - great for initial responsiveness of the site, but a nightmare for proliferating hundreds of simultaneous DB connections! Enabling the pooling feature provided by Drizzle (via postgres-nodejs) doesn’t really help much, because the instances of the “server” process don’t persist long enough to take much advantage of pooling, and in any case there isn’t any really anything to “share” between the instances anyway. At least, this is my understanding of the root cause.
Any thoughts on a good way to solve this problem? I could move away from Netlify entirely, and try to keep a single, more traditional single-server approach. At worst, this would slow down some parts of the site slightly, but would likely keep minimal database connections open (they could all be pooled for the single server). Or is there another way to keep the Netlify “serverless” architecture but somehow separate the SvelteKit “rendering” process from the “REST API” process, and get the API part to somehow handle more simultaneous requests, on a single (or very few) set of database connections?
20 Replies
Hmmm I might have solved my own problem 🙂 Supabase provides a Postgres DB but with their own automatic "connection pooler" in front of the database. Perfect for serverless setup like this. Each function invocation connects with its "own" client connection, but Supabase proxies the connection and re-uses connections to the actual database behind it. So far, seems to help a lot!
From the Supabase docs (Drizzle is mentioned specifically):
Every Supabase project comes with a connection pooler for managing connections to your database. The pooler provides 2 important services: It manages connections for applications that connect and disconnect from the database frequently. For example, serverless functions and ORMs such as Prisma, Drizzle, and Kysely often make and drop connections to the database. If they connected directly each time, they would quickly exhaust your database server's memory. To connect to your database efficiently with such tools, you need a pooler.https://supabase.com/docs/guides/database/connecting-to-postgres#connection-pooler I guess the only part that is maybe less clear to me is... should I be using pooling on the "Drizzle" side of things as well? Because I am now using Is there even any benefit in doing this, as opposed to using a normal "client" connection, since Supabase is going to handle the pooling anyway?
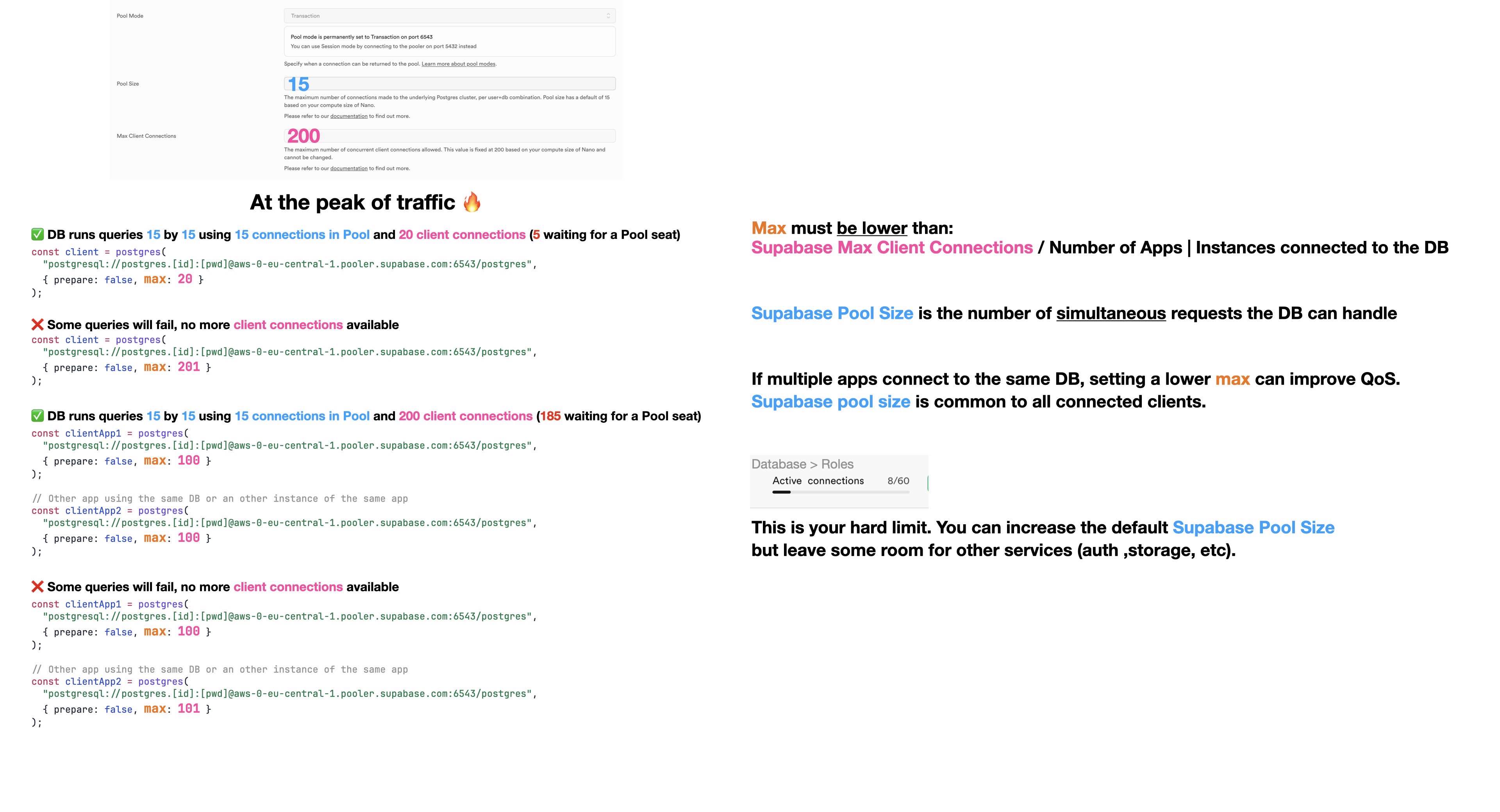
With Supabase, in a serverless context, Supavisor can handle 200 clients (base plan) and 15 simultaneous queries. 200 clients = 200 Drizzle clients with a pool of 1. The more you allow in your client pool, the fewer active instances of your server/function you can have.
If a serverless invocation = 1 handled HTTP request, you can then have a maximum of 200 simultaneous invocations.
I hope it helps 😅
Very helpful, thanks. Where does this graphic come from?
And I'm still not 100% sure I'm understanding the optimal relation between pooling on the server ("client") side vs the Supavisor pooling.
For example, if I configure Drizzle via postgres-node to use Pooling, does that mean that no matter how many queries comprise a single "transaction" (which could roughly correspond to "a serverless function invocation"), only 1 "client connection" will be established to Supavisor (out of 200)?
From me, after hours of debugging. I set up a demo project to test all of this.
there is also https://github.com/orgs/supabase/discussions/27141 to confirm / monitor your project
GitHub
How to Monitor Postgres and Supavisor Connections · supabase · Disc...
This guide explains how connections impact your Supabase database's performance and how to optimize them for better resource utilization. Installing Supabase Grafana Supabase has an open-source...
When you configure Drizzle with pg-node or Postgres.js and some pooling, it means that you allow Drizzle to run X simultaneous SQL queries.
if you set this number to 10, it means that you can't have more than 20 instances of this app (= the thing that create a Drizzle client)
let's imagine you have 20 instances: you consume 200 connections (pink number - supavisor max co).
the next thing that will create 1 more connection will crash.
Ah, so does it make sense to set the pg-node max to 1? Or is that a bad idea?
then, there is a second number (🤪): the blue one.
this one is how many simultaneous queries Supabase can handle
It depends 😄 If you have long-running servers (like fly.io, etc.), set the maximum according to how many instances of your app you can have.
ex:
If I set my max scale to 10, so, my config will be 200 / 10 = 20.
If it is a 'cloud function' or a similar thing (one request creates one function instance and then dies), you should set the max to 1 because this instance will only serve one user at a time.
If you have many Promise.all, it will slow down (1 by 1).
But in the end, at peak, you can't have more than 15 simultaneous SQL queries.
the only way to increase this number is to increase it in your Supabase dashboard (the Pool size). Supabase will warn you if it is too high (you have to keep some slot for Supabase services)
or sub to a powerful server
same for Supavisor: $$$
Right, so I am using Netlify, where roughly one function instance per "user", so pooling max:1 could actually be a good idea?
Yes, I think setting more will just force you to reduce your max scaling.
this is common to set 1 for short living functions
If you can set a maximum function invocation, I advise doing it.
and make sure that nothing else is connected to your production database (like monitoring or a dashboard, etc)
Take that into account in your calculations
Weeks ago, a friend of mine crashed his production environment by starting a localhost project with production credentials. 😬
200 + 1
If you want to try it yourself to better understand: https://github.com/rphlmr/supabase-drizzle-pool-size
oh, I get a 404 for that link!
oh god xD
private project. Sorry, I will make it public
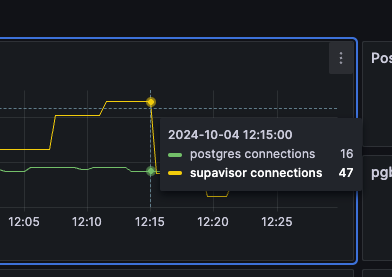
But I have just run a test now (set
max:1 for pooling) and didn't change anything on the Supabase side, and the "supavisor" connections have dropped significantlyfixed
yes! should be / 3 at least
before
after
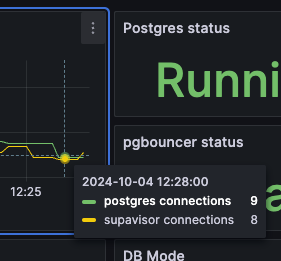
I have noticed that the Supavisor pool doesn't increase immediately. It takes 90 seconds after a connection close.
but thank you, this really helped me to understand better what is going on!
you are welcome!