Matrix Multiplication (matmul): `numpy` hard to beat? even by mojo?
Super interested in mojo and wanted to try out some of the documentation/blog examples. 

https://docs.modular.com/mojo/notebooks/Matmul
Great explanations and the step by step speed improvements are amazing to see!
However, in the end a comparison to a real world alternative is interesting. No one would seriously do matmul in pure python .
.
So I compared the performance to
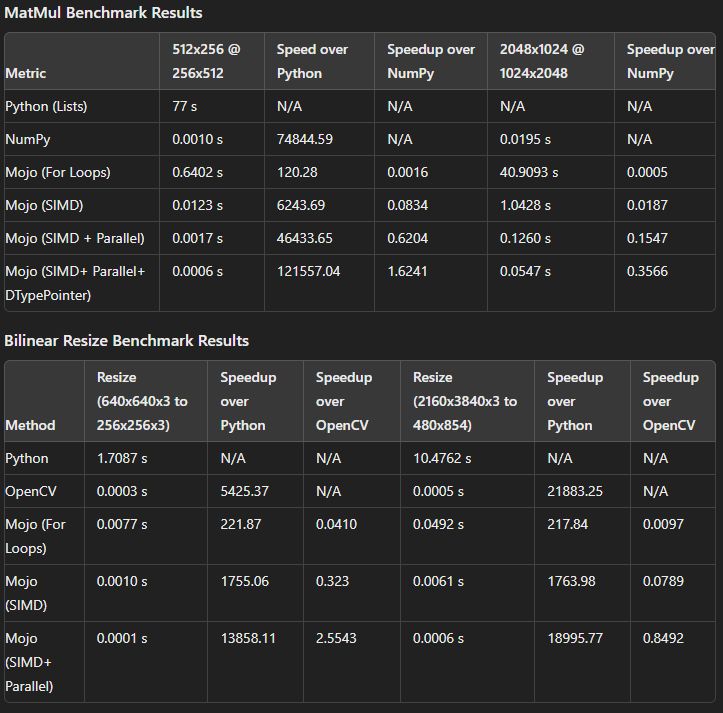
Results on my machine:
Does anyone have ideas for further optimisations to get mojo closer to numpy?
Is this something that only a framework like MAX or super low level bit manipulation can achive?
https://docs.modular.com/mojo/notebooks/Matmul
Great explanations and the step by step speed improvements are amazing to see!
However, in the end a comparison to a real world alternative is interesting. No one would seriously do matmul in pure python
.So I compared the performance to
numpy which is a much better "baseline" for comparison.Results on my machine:
- Naive matrix multiplication
- 0.854 GFLOP/s
- Vectorized matrix multiplication without vectorize
- 5.71 GFLOP/s
- Vectorized matrix multiplication with vectorize
- 5.81 GFLOP/s
- Parallelized matrix multiplication
- 35.2 GFLOP/s
- Tiled parallelized matrix multiplication
- 36.8 GFLOP/s
- Unrolled tiled parallelized matrix multiplication
- 35.3 GFLOP/s
- Numpy matrix multiplication
- 134.2 GFLOP/s
- gigantic speedup comparing against naive, pure python
- still almost 4x SLOWER compared to
numpy
numpy is so heavily optimised for this operation that there is little way to keep up or improve upon?Does anyone have ideas for further optimisations to get mojo closer to numpy?
Is this something that only a framework like MAX or super low level bit manipulation can achive?
Learn how to leverage Mojo's various functions to write a high-performance matmul.