Endia
Endia
Endia - Scientific Computing in Mojo 🔥
Endia: A PyTorch-like ML library with AutoDiff, complex number support, JIT-compilation and a first-class functional (JAX-like) API.
GitHub
GitHub - endia-org/Endia: Arrays, Tensors and dynamic Neural Networ...
Arrays, Tensors and dynamic Neural Networks in Mojo 🔥 - endia-org/Endia
46 Replies
this is incredible
I was worried you left since I haven’t seen you here in so long, but i’m glad you were working on this in the background 🔥
Super awesome @TilliFe!
This is amazing work @TilliFe !
MAX and Mojo are amazing! You are creating wonderful software. Thank you.
super cool @TilliFe 🔥
I just ran the benchmarks on MacOS
❯ max --version
max 24.4.0 (59977802)
Modular version 24.4.0-59977802-release
❯ mojo --version
mojo 24.4.0 (59977802)
and noticed the Loss is significant smaller for MAX JIT compilation:
Running MLP benchmark in eager mode.
Iter: 1000 Loss: 0.22504070401191711
Total: 0.0069106340000000023 Fwd: 0.00096554800000000021 Bwd: 0.0015250959999999984 Optim: 0.0023210129999999963
Running MLP benchmark in a functional eager mode with grad:
Iter: 1000 Loss: 0.25778612494468689
Total: 0.0048792460000000003 Value_and_Grad: 0.0027390779999999994 Optim: 0.0021332430000000025
Running MLP benchmark with MAX JIT compilation:
JIT compiling a new subgraph...
Iter: 1000 Loss: 0.061800424009561539
Total: 0.022694156999999975 Value_and_Grad: 0.020552729000000027 Optim: 0.0021339400000000013
The weight initializations of the neural networks might be a bit unstable. (randHe initialization) If you run the benchmarks a couple of times, there shouldn't be any outliers on average. Can you try that? Let me know if you keep encountering these inconsistencies.
here the results of 10 runs ... the Loss of MAX JIT is not always the lowest , seems to depend on the random weight initialization as you said already ... if you want to extend the benchmarks to calculate averages over multiple runs i am happy to run another test ...
Please go for it. Great! Averages would be most valuable.
If you feel like adding these benchmarks to the Endia
nightly branch afterwards, fell free to make a pull request. At best as separate files to what is already there.
On a small tangent: You can also run the JIT compiled version without MAX, which then uses the same built-in caching mechanisms but does not send the graph to the MAX compiler. The graph is run directly with Endia's ops. At the moment this should match the speed of the eager execution. 🚀i can give it a try but would need to digg into your implementation - basically the weights would need to be initialised for each of the 1000 loops I assume - straight forward for mlp_func and mlp_imp it seems, for JIT, i will try 😉
You don't need to dig into it the JIT mechanism. The functional version and the JIT-ed version is one and the same. The implementation only differs in a single line of code. Let's clarify.
In the regular functional setup it works as follows:
0. Initialize all Parameters with e.g. rand_he initalization (i.e.a List of nd.Arrays, i.e. a bias and a weight array for each layer)
1. Define the forward function (fwd: a regular Mojo function with a List of arrays as the argument)
2. Pass this fwd function into the nd.value_and_grad(...) function, which returns a Callable that can compute the logits/loss and the gradient of all inputs at the same time.
3. Pass all initialized params (from step 0) into this Callable. This will actually do the work and return Arrays (i.e the loss and the gradients).
So the initialization of the weights happen before you do all the work. The only difference between this functional mode and the JIT mode is that we pass the value_and_grad Callable after the step 2 into the nd.jit(...) function. So you don't need to worry about this actually.
Step 2 explicitly, the regular way (line 73 in this file):
vs. the JIT way (line 73 in this file):
@TilliFe Just committed a PR with a simple implementation of multiple runs of the benchmarks to calculate average results. Feel free to use it or modify it as needed. If it doesn't fit, just ignore it. 😉
@TilliFe This library looks awesome! Just curious--there's a lot of focus on JIT compilation in the docs. Are there any limitations on AOT compilation for Endia?
Eager Mode: Iter: 10 x 1000 Avg Loss: 0.22449450194835663
Functional Eager Mode with Grad : Iter: 10 x 1000 Avg Loss: 0.28279870748519897
JIT: Iter: 10 x 1000 Avg Loss: 0.099444642663002014
@James Usevitch Thanks.
AOT vs. JIT in Endia:
All computation graph related things in Endia are fundamentally done JIT. However, Mojo itself seems to be a hybrid approach of mainly AOT, with the possibility to do JIT compilation.
When using Endia in eager mode, the main building blocks, i.e. most primitive operations, are compiled AOT (matmul, add, relu, ...) and then chained together at run time. I spent a lot if time thinkig about how to design Endia to be as modular as possible: You can now define (Differentiable) Operations and make them as large and complex as you wish to. For example, have a look at the mul operation in the functional module. It is easy to see that we can define more complex functions like fma etc. with the same approach. These primitive submodules are then compiled AOT.
Compare that to doing JIT compilation with MAX, where we merely capture the operations that need to be performed, send this endia graph to the MAX
compiler, let it do its magic, and take this compiled MAX graph as a new Callable and cache it for later reuse.
GitHub
Endia/endia/functional/binary_ops/mul_op.mojo at main · endia-org/E...
Scientific Computing in Mojo 🔥. Contribute to endia-org/Endia development by creating an account on GitHub.
Thank you for that! I looked into it and could not find any obvious reasons for these differences.
However I realized that the way the loss is put out in the first place has been kind of flawed so far. Until now, it was simply averaged from the first to the last iteration and since the loss can be extremely high in the first couple of iterations, the average output at the end is not representative at all of how the loss evolved and decreased over time. In the the new nightly we print out more intermediate loss values and can see, that the number actually falls fairly equally in both the MAX execution and the Endia execution mode and end up at around the same values of around 0.001-0.01. Nonetheless, there is still a very slight difference and the loss of the MAX execution still tends to fall a tiny bit faster. This might have something to do with the internal implementation of the MAX ops (which I would really like to know more about).
re: Your pull request. I will try to merge/integrate your changes as soon as possible. I like it.
Congrats @TilliFe, you just advanced to level 5!
Introducing: Custom Ops 🛠️
If you want to learn more about how to define your own Custom differentiable Operations in Endia, you can checkout the updated Docs Page here: https://endia.vercel.app/docs/custom_operations.
Defining custom ops is actually much easier to do in Endia than in Jax or PyTorch without giving up on all the low-level control that you need to make your operations go brrr.
Custom Ops is what i meant in my previous answer 😀TilliFe, custom ops are 🔥. I'm loving your work here. What is your background working with JAX?
Apart from studying their Docs Website, not a lot.
I really like the philosophy of both PyTorch and JAX, but i do not see any reason why one approach would be better than the other, it simply depends on who you are asking I guess. Realizing that functions in Mojo are treated just like regular values gave me the idea that this JAX-like interface must be possible.
What I can say about the development of Endia in general, is that this project started in a really naive way (as you might have seen last fall with the Infermo project.) Since then I kept working on it very consistently, rethinking and overthinking all aspects of the AutoDiff Engine, again and again.
So all in all, I wouldn't call myself an expert in neither JAX nor PyTorch, I simply build things how they seem most reasonable and intuitive and hope to be able to continue working like that in the future. 😉 I am still learning a ton.
well you're doing great work! FYI, one of the things we're working on is to make it so the max graph api propagates shapes implicitly as part of graph building, even when they are parametric. This will get rid of the unknown dimensions, and elimiante the need for "shape op" operators etc. I think this can also allow a pretty nice UX because we can report shape errors at graph build time instead of at graph execution time.
reamde
nice :]
Interesting, really looking forward to it. 🤗 This would make it much more flexible. Nice!!!
On this tangent: Here is how shapes are handled in Endia during runtime: At the core of it all, we have the
Dual-Graph. Endia always constructs two separate graphs, one for the shape computations (ShapeGraph) and one for the actual data computations (DataGraph). Each ShapeNode has a dedicated method to compute its data (dims, strides, offset) during runtime based on its parents.
On the other hand, the DataNodes in the DataGraph also perform dedicated data transformations based on their parents, however every DataNode additionally holds a reference to exactly one ShapeNode. This way we can clearly separate concerns and can compute shapes without properly initializing any DataNode. This development was crucial to take the step from pure eager execution to efficient function tracing.
👉 I updated the Custom Ops Docs Page with the function clone_shape in the array registration to illustrate this concept.Endia v24.4.1 Release
New:
- Reduce Ops: max, argmax, min, argmin
- Spacial Ops: 1D, 2D, 3D Convolution, MaxPooling, AvgPooling (usable, yet fairly unoptimized and not properly plugged into the autograd system - coming in the next release.)
- Improved documentation and licensing.
👉 Details: https://github.com/endia-org/Endia
GitHub
GitHub - endia-org/Endia: Scientific Computing in Mojo 🔥
Scientific Computing in Mojo 🔥. Contribute to endia-org/Endia development by creating an account on GitHub.
Endia v24.4.2 comes with a more familiar API than ever before.
Check out a small video about it on X: https://x.com/fe_tilli/status/1819100569425899659
TilliFe (@fe_tilli) on X
Spot the difference! 🙉
Mojo @Modular is feeling more pythonic than many people think!
Endia - as a new ML framework in Mojo - is a proof of concept that not all good things need to be in C++ and Python: https://t.co/fD2OWBxU7t

Twitter
Super basic question: I see your package compiled ... can't seem to import it.
import endia as nd
is giving an error because mojo can't locate the package.
How do you tell mojo the path to load a package?
Good question, lets first test if the import of modules work at all on your machine, then we try to generalize this for any kind of external module that shall be used in a (nested) project.
Basic Import Test:
Create a new directory
test and copy the endia.package inside of it. Then next to it create a file where you try to import endia. If that works you can checkout the next step.
Example:
General Usage:
- If you build a nested module/a project with a lot of subdirectories, make sure that all subfolders that use an external module (e.g. Endia) have a __init__.mojo file. This will modularize the subfolders. Check out the docs for more information: https://docs.modular.com/mojo/manual/packages.
- Once you have modularized your project, you can place the endia.package at the top level of your directory. Then you should be able to import endia at any level.
Example:
Endia nightly now uses MAX/Mojo nightly. This was long due. 👷♀️ 👷♂️ 🧙Nice, that will make things a lot easier. 24.4 is pretty old by now 🙂 🙂
TilliFe (@fe_tilli) on X
From forgotten handwritings, through a rediscovery in the 1960s (for detecting atomic tests 💣), to its ubiquitous presence in modern technology, the FFT is one of the most impactful and elegant algorithms ever.
Here is a slick implementation in Mojo 🔥: https://t.co/K0dcwR1XNr

Twitter
The plot below illustrates speed comparisons of 1-dimensional FFTs across various input sizes, ranging from
2**2 to 2**22. (Measured on an Apple M3).
Endia's FFT implementation, despite its compactness, delivers performance not far behind established frameworks. Further optimizations and algorithmic refinements could push Endia's performance to fully match or even exceed existing solutions.
Hey @TilliFe, amazing stuff! The plan was to do FFT for the next Mojo Marathons, would you be open to me using Endia as the benchmark / testing framework? Hopefully this could expose some more people to your work and ideally push the algorithm even further, let me know if you are interested
Absolutely! :mojo: I had a similar idea and wanted to reach out to you on that as well.
Perfect, i’ll dm you in a few days and we can talk more, thanks 🙌🏻
partying in nd-space...
https://x.com/fe_tilli/status/1829431929688465500
TilliFe (@fe_tilli) on X
I started working on Endia (formerly named Infermo 💥) exactly a year ago. Mojo/MAX @Modular and Endia have come a long way since then. What a fun and insightful journey!
https://t.co/kX6NJXTeGB
Twitter
I fixed JIT compilation with MAX. :mojo:
What was the problem?
If you previously ran the simple MLP benchmarks inside Endia's
benchmarks directory, you might have noticed that the version using MAX for JIT compiling Endia Subgraphs, took for ages compared to not using MAX. Why? When transferring data from the Endia Graph to the MAX Graph/Model and back, we did not properly make use of TensorMaps, but converted arguments (a List of Endia Arrays) to a list of NumPy arrays first (a List of PythonObjects, expensive!), which are then again being converted to a set of MAX Tensors for further use by the MAX engine). This sounds indeed terrible 🤦♂️ and I only saw the obvious alternative now: We can create MAX Tensors as inputs to an executable MAX Model which do not own their data pointer! From now on, the inputs to a MAX Model merely borrow UnsafePointers from Endia Arrays for the duration of the MAX Model execution. Additionally, outputs from a MAX Model were previously copied (also super expensive). Now, since those outputs will usually be destroyed, we can just steal the outputs' UnsafePointers and let Endia Array own them after execution.
All in all, there are no unnecessary data copies anymore, and Endia and MAX can now work on the same data. This dramatically speeds up JIT compilation in Endia. Due to MAX' highly optimized ops, this speedup will be especially significant, when training larger Neural Networks. Ultimately, this also gives me confidence, that Endia can greatly benefit from using MAX once it'll support GPU. Cheers! 🧙Model | Modular Docs
Represents a model that's loaded and ready for execution.
amazing, great work TilliFe!
Exciting project. :mojo:
@TilliFe In your Endia Stack Concept image https://raw.githubusercontent.com/endia-org/Endia/nightly/assets/endia_stack_concept.png
machine learning is a box above the Endia box. Does that mean that functionality like in torch.nn won't become part of the core Endia lib or are you planing to integrate functions to build and train neural networks.
Hi Martin, I am indeed planning to integrate those features, at least on a high level. Things like high level modules and some standard nn models.
The image shall simply display some possible applications (stuff I am personally really interested in), but it definitely does not cover all possible applications of a comprehensive Array library. (Just look at where NumPy is used nowadays, even in satelites floating through space...)
Thank you for mentioning this, I should write down something like a roadmap to make things more transparent.
A small update
https://x.com/fe_tilli/status/1835592247779193091

{kind=link}
Amazing work TilliFe!
@TilliFe is there any documentation on allowed operations (including, in particular — any operations which deal with control flow) for Endia?
Separately — as part of your JAX implementation, I’m wondering if you support e.g. user defined program transformations & “functorial” dataclass abstractions (like Pytree, for instance, from JAX)
The second (a Pytree like thing) is less important to me. I’m a PhD researcher in ML/PL — and I make my living wages off of program transformations (so that’s the one I care most about)
If this isn’t supported yet, not a big deal — I know how JAX works pretty well so if I have some free time I could attempt to hack together something (if this is of interest)!
If it’s important to motivate why user programmable program transformations — I can furnish a bunch of examples from probabilistic programming and AD (extensions, not just on deterministic functions — but to things like, say, expectations over measures)
Hi 🧙, at the moment I'd prefer to answer that it is still a bit too early for these kind of flexible transformations. I am currently overthinking most parts of the endia core and I am planning to rebuild things from scratch (again). So things will hopefully become better and more flexible in the next iteration. Wrt. to custom transformations, I would like to refer to Endia's
custom_ops as described in https://endia.vercel.app/docs/custom_ops.
Nonetheless, I wrote out a little program which basically gives a more or less comprehensive overview of what Endia can currently do in terms of function transformations and how one might apply control flow:
1. We create a function foo which has some control flow inside of it.
2. We create a jitted (optional, but for the sake of concatenating transforms let's do it here too) version of this function and pass it to the grad and jacobian function transformations.
3. Then, in the three following rounds, we use those transformed functions (which are basically just a bunch of custom structs called Callables) and pass a differently initialized x into them and check if the transformed versions branch correctly.
I am not sure i f this helps you in any way, if not let's just take it as a checkpoint on what Endia can currently do and what not. 🙃
I'd be super happy to hear more of what exactly you would like to see in the long term. Could you create a list of features (possibly with some examples) so that we all can learn a bit more about the powers of function transformations. That would be super awesome! :mojo:Thanks for explaining!
Will send some examples when I have a bit of time —
Endia (@endia_ai) on X
How to differentiate any function/program arbitrarily often (in Mojo)? 🙉
1. Define a low-level forward pass
2. Compose a high-level backward (vjp) function
3. Register the new op
Learn more: https://t.co/ArO3pJ1qvI
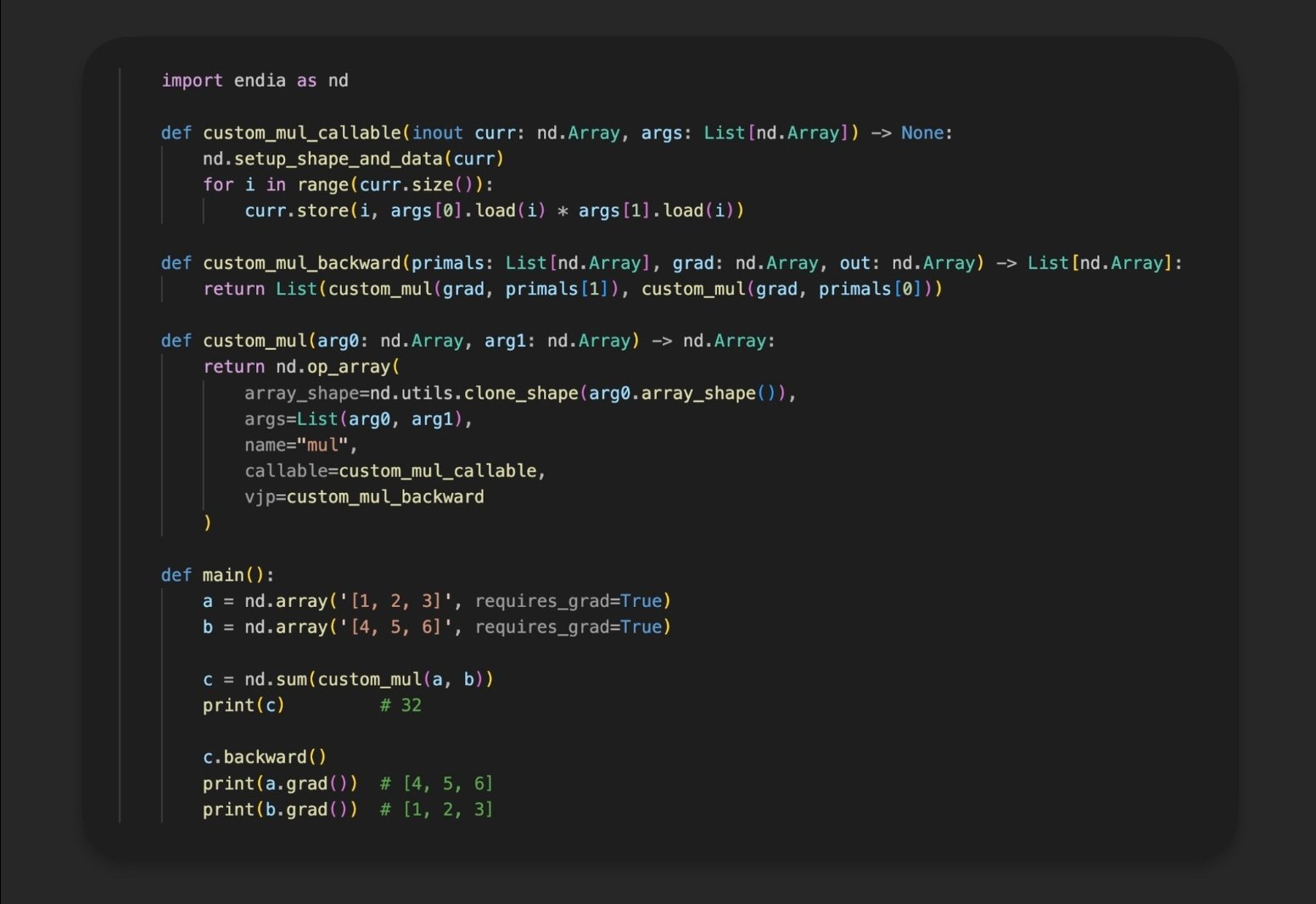
Twitter
I am currently trying out a lot of new stuff for Endia in private, I will post some updates soon. Chears!
Hi everyone! 👋 Since a couple of people have reached out in the last week asking if I'm still aiming to maintain Endia: the answer is a clear YES! A lowkey update to Endia 24.6 is due, and a more interesting update is planned for January or February.
As promised, a small update: Endia 24.6. Nothing crazy at all.
Endia is now available via Magic! 🎉
- Works in environments using Mojo 24.6 or higher.
- Make sure to add
"https://repo.prefix.dev/modular-community" as a channel in your .toml file.
Thanks @Caroline for your help! 💫
A short demo: https://x.com/fe_tilli/status/1879492176457167241TilliFe (@fe_tilli) on X
We can now (experimentally) use Community Packages in Mojo @Modular via Pixi @prefix_dev 📦.

Twitter