Performance questions
I'm using Drizzle ORM with Planetscale DatabaseJS driver and my application has spots where I want to decrease number of HTTP requests to my database. I have following questions:
1. Does Drizzle+DatabaseJS make separate HTTP request for each query? (I know I should be asking this question to DatabaseJS creators, but asking here in case someone is aware of that)
2. If it does, what would be the best way to group several queries so that they are performed in one HTTP request?
32 Replies
1. Yes
2. That'd require batching implementation which we currently don't have
Out of curiosity, what's the reason behind decreasing the number of HTTP requests?
Thank you for your answer
In my understanding, each HTTP roundtrip will add additional overhead resulting in increased response time. I have spots in my application where I want to achieve as quick response as possible. I know I can do that using your
sql operator, but it does not provide type-safety which is not good
Basically, in my current case I need to perform several inserts into different tables. Maybe any way to build query using Drizzle(to ensure type-safety) then turn it into SQL and execute in one request?
It would be great if I could do something like
this
Inside of MySqlInsert class I see following methods. Maybe I can use one of those for my use case?
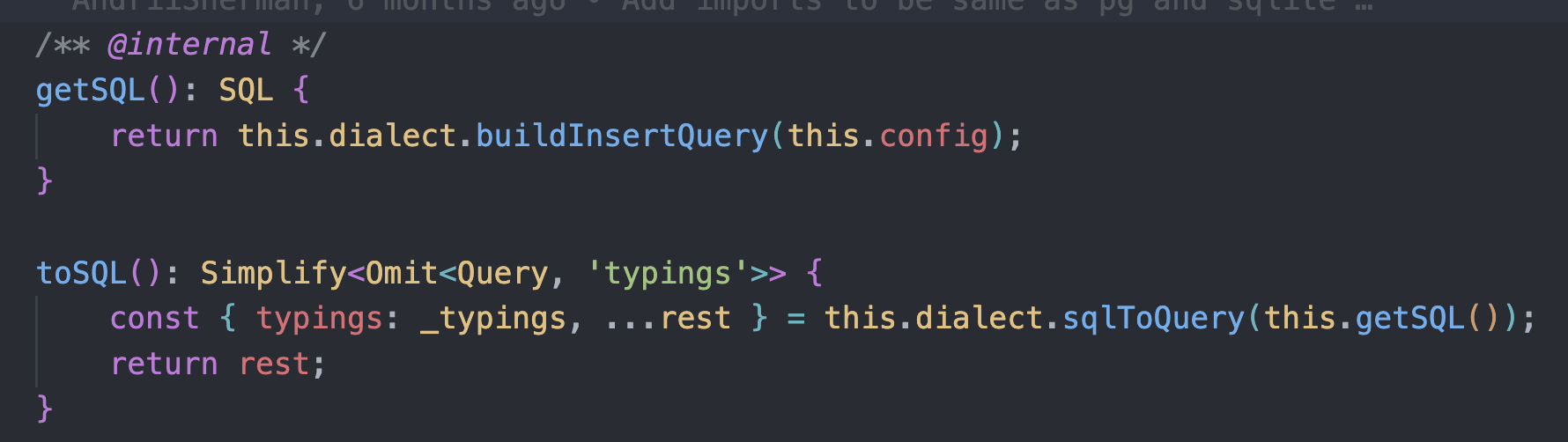
As far as I can see, I can get an object consisting out of query and params. For now I can't find a way of turning this staff into plain query
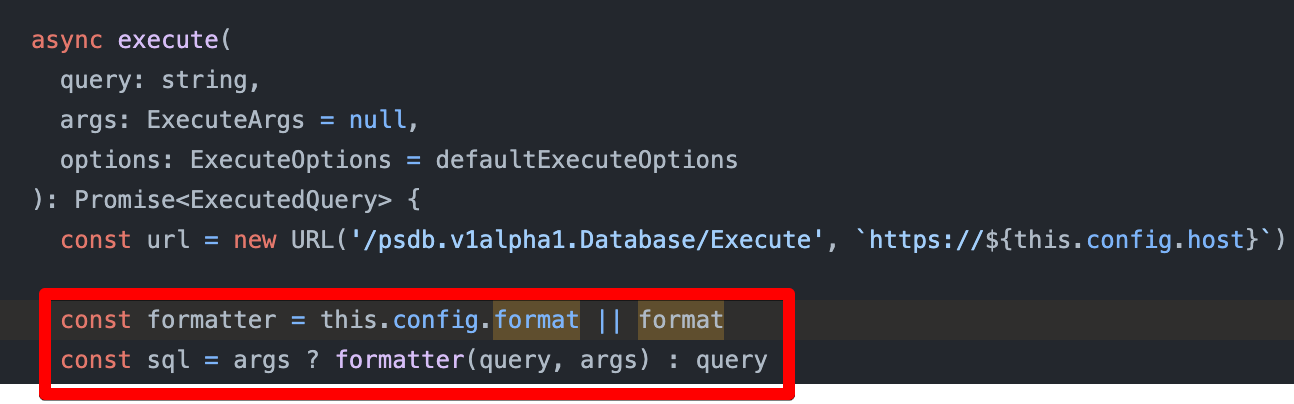
So you are passing query and args separately to Planetscale driver directly and they use their formatter(if no custom is passed) to transform it into query. Maybe I can reuse it to transform drizzle query into plain SQL and then execute it
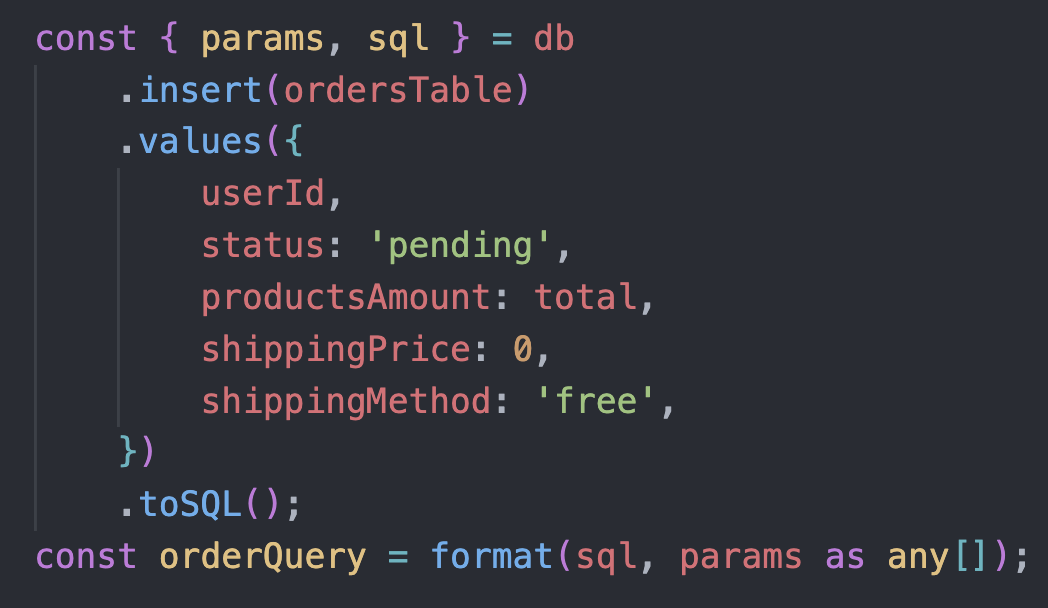
@Dan Kochetov Using the code below I was able to transform it into query. Only thing is that I had to use
as any[] but it should not be a problem since Drizzle handles type-safety anyway. As far as I can see queries are not prepended with semicolon. Construction on second ss should result in working query, but haven't checked in runtime.
What do you think? If it's too cringe pls don't ban me ;D
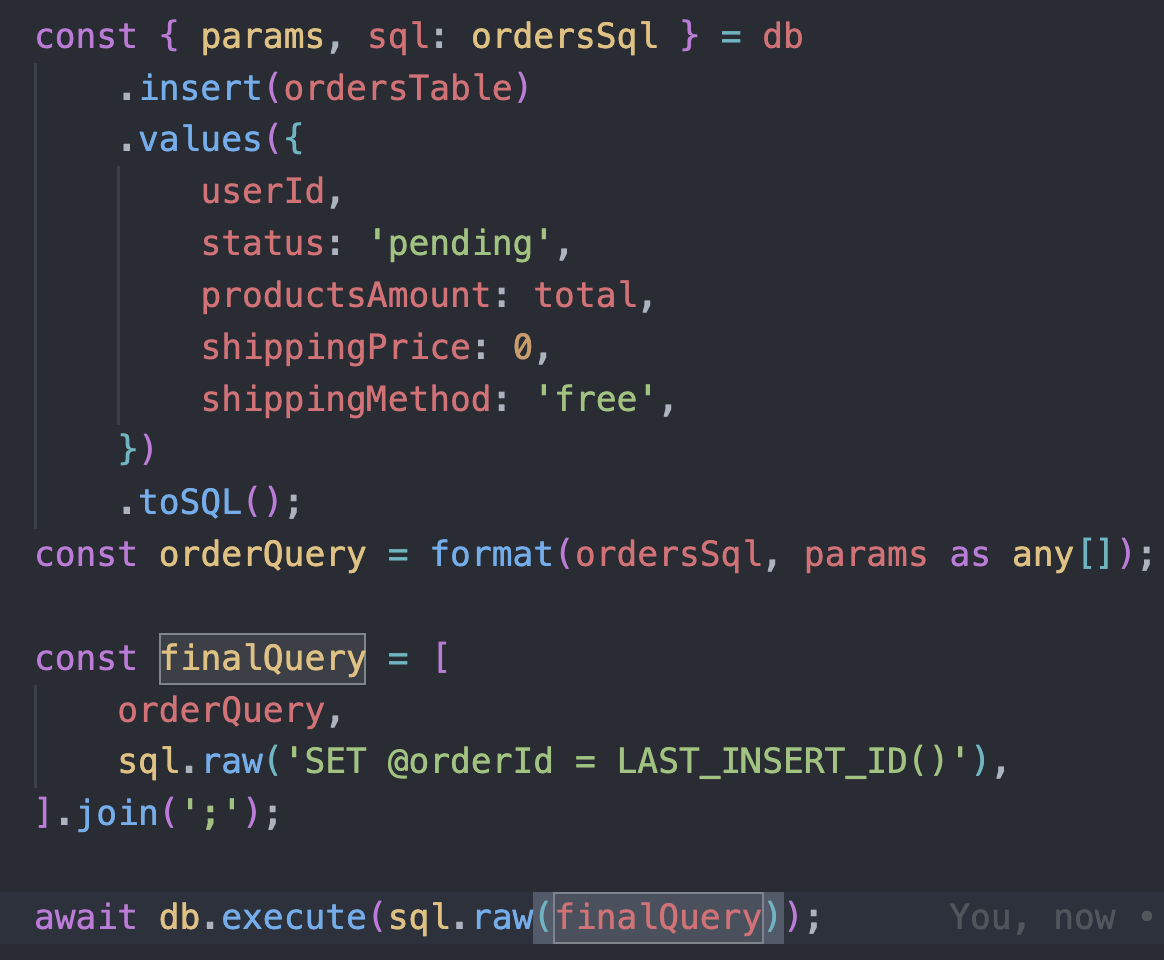
If the driver supports running multiple statements in a single query - sure, go for it, looks like a good enough replacement of batching
if those queries don’t depend on each other, i use promise all
promise.all just runs the queries in parallel, it's still multiple HTTP requests
if your goal is to decrease latency, it's fine
@BREAD have you considered edge runtimes? In my case, the cold start time of lambdas node runtime is where most of the overhead occurs. In edge runtimes though, the cold start is milliseconds. From there, Most multiple round trips to the database are near-negligible difference on total duration. As long as the edge runtime region is limited to be near the PlanetScale MySql server (both in US-east in my case)
@mcgrealife thanks for tip. Will definitely try it out
worth noting that CloudFlare recently announced “Smart Placement” which automatically puts your worker closer to the database source.
working great for me with planetscale
@Dan Kochetov Hi, have another question regarding performance. It is related to relational queries.
I have following code:
It results in query I attached in the file query.txt
The query explanation is attached in the form of screenshot
Judging by query explanation it seems like such query structure is not able to leverage indexes on tables and performs full table scans
Is there any way I can optimise it? As far as I can see in the docs (https://orm.drizzle.team/docs/joins) simple drizzle joins does not use JSON functions and aggregations. Are there any plans on optimising relational queries?
Joins [SQL] – DrizzleORM
Drizzle ORM | %s

Indexes usage depends on a lot of factors, including number of rows in the tables
Query planner might not always use an index even if it can be used, if it thinks it'll be more efficient not to
@Dan Kochetov Even if we ignore indexes, it looks like Drizzle in the case of relational queries relies on multiple subqueries that does not have any constraints. Meaning that each subquery will select whole table. In addition, if we take a look at my case, I need to select orders that are bound to specific customer, but as far as I can see, the query built by Drizzle will select all orders with all joined and aggregated data using subqueries and only then will perform WHERE lookup on resulting derived table. Since this table is derived, not an original one stored in DB, it makes sense it does not utilise indexes, since there are none
Are you sure it works like that in the query planner? For example, the query planner in Postgres is smart enough to optimize those queries properly.
@Dan Kochetov I'm using PlanetScale which uses MySQL under the hood. As you can see in query explanation(I've used EXPLAIN <query> to analyse it on DB level) the outermost derived table, from which final select with WHERE clause happens, is estimated to have ~98k rows(I have ~100k records in
orders table right now). The type of JOIN is ALL meaning full table scan is performed. Additionally, in 3 cases out of 5 type of JOIN is ALL. In these three cases relatively large amount of rows is expected to be returned. And in the same three cases no index is being used. In two cases it uses filesort for full table scan
I see, I'll think about it
@Dan Kochetov Btw, also noticed, that such query results in large amount of row reads. I also guess that it will only grow with tables size the query is performed against. To compare with, simple query with two joins(that should return the same data, just in different format)
Results in only 4 reads and this amount should not depend on table size, but on number of rows connected with each other(orders->order_items->products)
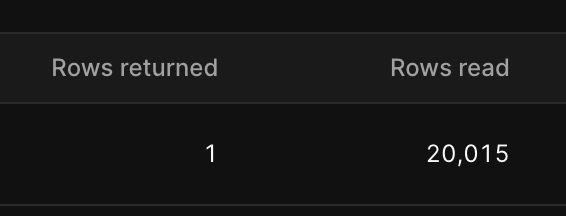

Got it. Yes, this is expected, if indexes are not used. I'll look into how it can be improved. Thanks for investigation!
@Dan Kochetov I've played around and thought about how can it be optimised and may suggest couple of ideas. Hope, you will find something useful here
The first one is based on fact that Drizzle tries to perform only one query to retrieve all relational data. I changed a structure a bit so that it takes advantage of indexes. Example and result are attached. Query explanation as well. So there are two major changes. Firstly, WHERE clause with the main condition is used in outermost subquery, which actually selects from main table
orders. It allows query planner to utilise index. Secondly, subquery used for left join is kind of simpler version of outermost subquery. It selects orders by user_id but also joins order items. Such structure allows to utilise the index in here as well. The resulting data format looks like the one drizzle can handle right now. The idea here is to use subqueries that are able to leverage indexes. In query explanation you can see that the estimated amount of row reads is minimal. On the other hand, such structure implies repetitive queries resulting in reading the same rows several times, but it is still way less than selecting whole tables
The another idea I had is from 'Keep it simple stupid' category and might not be compatible with Drizzle mindset. Separate queries(4th screenshot). Such approach will allow to keep amount of row reads at minimum, no complicated queries need to be built for deeply nested relations. From disadvantages: such approach completely differs from what Drizzle is currently doing; multiple queries/roundtrips are going to be needed instead of one(the amount will grow depending on depth of relation to select); additional overhead on client(especially when selecting large amounts of data since each step is being returned to client )


Thanks a lot for the effort you made! However, I'm not sure this approach can be applied, because the query you've optimized solves a specific case, and I don't think it can be applied to the general case.
I see that you've put the
where clause in the innermost subquery, which works for your particular case when you're only filtering by the orders table column, but it's also possible to filter by relational fields that are added in different subqueries (and we're considering implementing filtering by deeply nested relational fields as well). That's why I've added the where clause to the outermost query instead, where all the relations are joined. Also, since our where API accepts any SQL condition, it wouldn't really be possible to split it based on the column to, for example, add the user_id condition to the inner subquery and move the rest to the top.@Dan Kochetov Hm, maybe it's possible to think about it in following way:
1. Every relational query starts from some main table. In current case
orders. Condition applied on this level is applicable to main table only. Let's call it main condition
2. Each time Drizzle goes deeper it builds subquery for LEFT JOIN. Each such subquery contains main condition to make sure we select only relevant data from main table and make use of indexes. In case some additional condition on relation is needed, it can be added as usual(using Drizzle where API). Since it is being applied on specific relation, it will be used only there, I don't think it has to be repeated like the main condition. Relational query config has nested nature, therefore 1st level condition have to be applied to 1st level relation and so on(I attached query example where I added conditions to order_items and products)
If I properly understand the meaning of filtering by deeply nested relational fields then I believe it should be possible to implement it using suggested structure. As I already mentioned, condition will be applied to respective subquery where table, being joined right now, is introduced
Is there a specific reason, why you want to apply conditions after relations are joined, not before/in the process of it (like I did for order_items and products)? In theory, if we need to filter out specific, let's say, products, why not doing it in subquery where this table is being introduced?
Is there a specific reason, why you want to apply conditions after relations are joinedbecause all the conditions are applied at the same time (it's a single SQL chunk), and it's possible that one of the conditions may reference a relation field that is only joined in one of the outer subqueries and thus is not available in the innermost query. Also, the query you've sent uses two joins at the same level, which won't work I've implemented it like this initially, and it resulted in items duplication in the result You need to add one join per subquery for this to work correctly the
where condition is defined like this (for example):
So here, there are two conditions, one of them can be applied to the innermost query and another one cannot, because it references a relation field that is joined in one of the outer subqueries.
Since we can't split the condition (it can be any SQL expression, really), the only solution is to always apply it to the outermost subquery, that has all the relations joined.@Dan Kochetov I see in current implementation Drizzle relies on multiple GROUP BY. Can we not use it to ensure that only distinct records will be selected
Not really sure, this requires further research
@Dan Kochetov To clarify, will these two WHERE clauses be combined and applied on the same level?
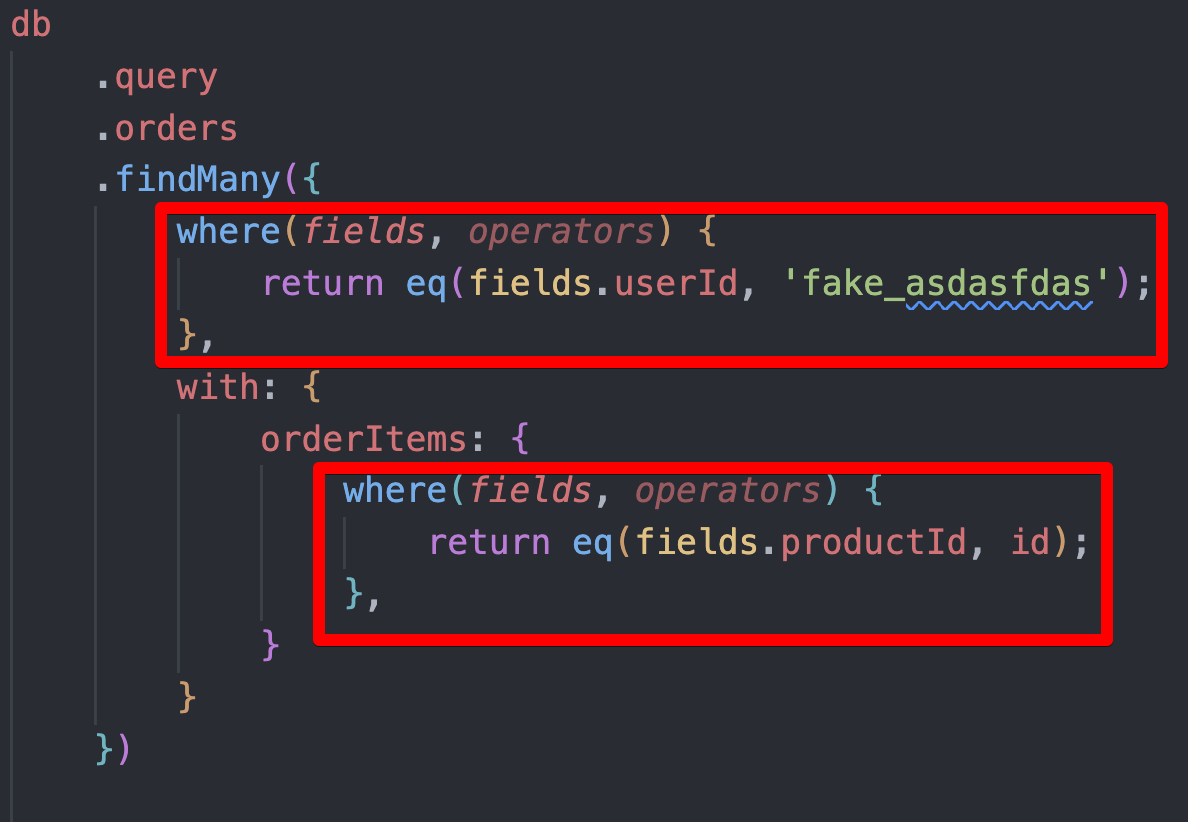
If the conditions would be scoped to the subqueries, there shouldn't be an issue with referencing table that is out of scope, if condition is built following Drizzle's type hints
Regarding your condition example
Well, if I understand correctly,
sql operator does not provide any type-safety and therefore should not be treated as a tool that provides guarantee because the user is in complete control and can pass anything in there whether it's correct or notno, see the example condition I've provided. It's what you can specify on the root query level, and it uses fields that come from subqueries from different levels.
@Dan Kochetov As far as I understand, this example filters order that have less than 0 order items. The same can be achieved, but using the HAVING clause (condition is different because in my case there can't be order with no items). Not sure if in Drizzle query I can access specific column, maybe with JSON functions but I'm not familiar with them enough. It is also possible to filter specific values without relying on JSON functions(check last two screenshots). It is still not possible to access deeper level joined table
orders_orderItems_product but it seems to me that it's not possible in Drizzle either. Let me know if I'm wrong



how is this strategy working for you to batch multiple statements together?
also what is that format() method you are using? did you implement it or is it a lib?
Hey, didn't try it out myself. The format() method was taken from the planetscale driver if I remember correctly