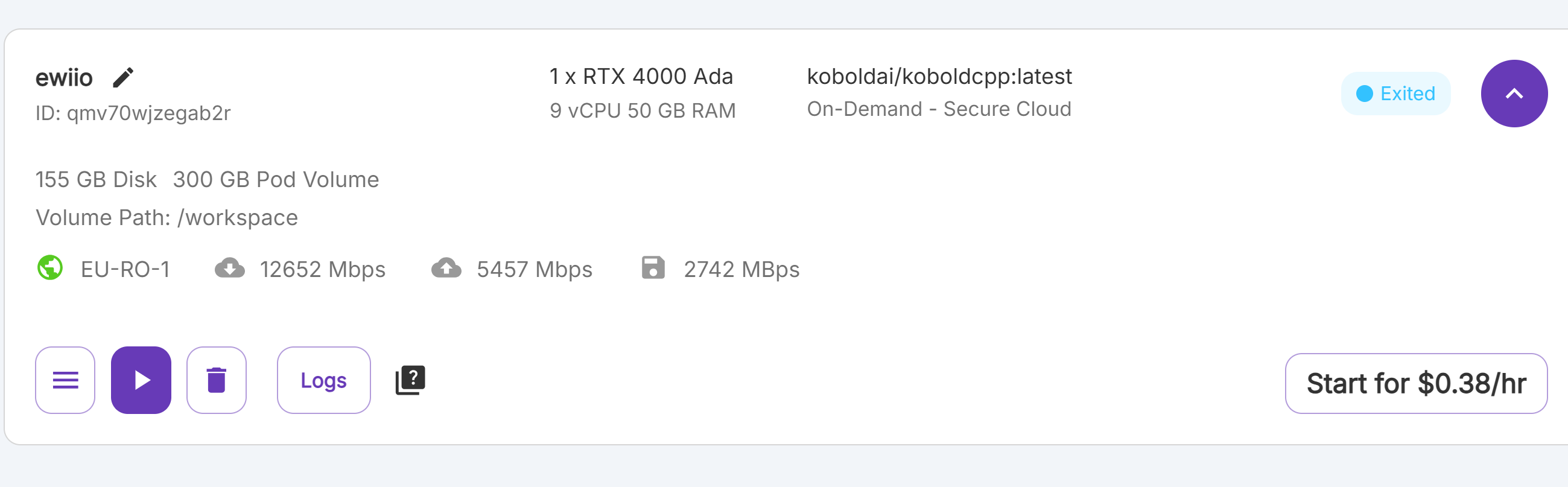
Struggling with runpod unable to access htpp server or terminal error.
Hey guys! I have posted this same issue some time ago, but I cannot use any of the pods at all when I try to run Kobold AI with Fallen Llama or any other Model.
The first time I used this I been able to access runpod normally, but after a few days I am dealing with the runpod issue ever since.
I have this for my screenshots.


42 Replies
Currently switching to a 2x RTX 4000 Ada to see if a lack of GPU's might be the issue.
Edit: Wait nvm still same crap.

It says oom
Oom means you need better gpus with more ram
Right @Henky!!
Out of memory indeed
Without the rest of the log its hard to say
Which is fallen llama tho
Oh it's a custom llama 3
Its a 70B
Ic
Which will fit on a single A40/A6000 if its Q4_K_S / Q4_K_M
I suspect a to large quant was used
Verified the model can run
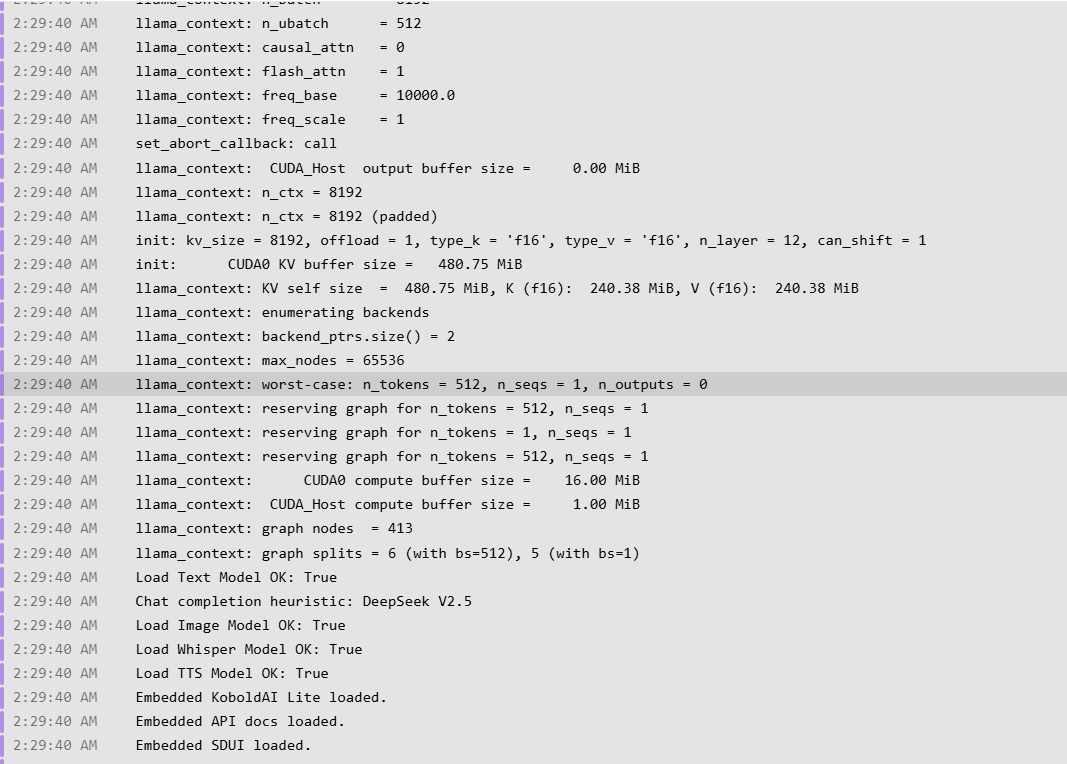
Its apparently a Deepseek 70B Distill finetune
Kobold auto picked it up as deepseek
Link I used was https://huggingface.co/TheDrummer/Fallen-Llama-3.3-R1-70B-v1-GGUF/resolve/main/L33-Tiger-R1-70B-v1b-Q4_K_M.gguf?download=true , on a single A40
Its quite close so if you want more than 4K context you will have to go higher than the 1xA40
With short context lengths yes
So my problem could be solved by potentially using max GPUs available and after that it would get the http running?
You need 48GB for Q4 at 4K on 70B's, you only went up to 32GB so it crashed
try 2xA40 first
Hey river! I have finally had some time to get this done, and I switched to 2xA40. It did load everything, and the terminal started working, but the http service still didn't work. I ended up deleting the pod because I don't want to spend too much to maintain this.
Here's the text logs.
The log is cut tho
only shows the installing part
Dang
Can't access the pod to re-download now coz I got rid of it lol
lol
Do you think the http service not ready issue I had earlier was mainly because of low ram or something? Happened for so many pods. I thought fixing the out of memory issue would deal with it but I got the same Http service is not ready issue
what was your model context length
like the one you set
I wasn't sure. Didn't pay attention tbh
Just chose my template and the model and thought things would work out since they did before
Check your logs to figure out why the program isn't running, that's why port isn't ready
The log cuts off right before the context portion, either you didn't wait long enough or you put to much context and overflowed the GPU. How much context did you put?
Or wait I can see it
You put 65K context, which is probably to much for 2xA40
The single A40 could only handle 4K context at Q4_K_S
And for most normal use cases your never going to hit 65K
Interestingly 65536 does fit for me on the Q4_K_S link I posted
Seems to fit in Q5_K_S as well so I think you actuallly shut it down right before it would have finished loading
The main reason it took a while is that whatever pod you rented didn't have great download speeds, secure cloud downloads a lot faster
The http only comes online once its 100% loaded
how did u see it tho
Theres a line with all the parameters it got assigned
oh you hav to download it
lol
im stupid
It was likely 1 minute away from working
this
I get it though, download took over 10 minutes on what I assume was community cloud, probably only clicked the log after that seeing it had finished downloading not realizing it only just finished
The log said that everything was completely downloaded at the end, so I thought there was something wrong with the pod itself
Nope just didn't wait for it to load
It shows cloudflare links when its done
I see. How should I know next time in the logs it actually finished loading everything? It was hard to tell
Your asking it to load 48GB of model so that always takes a bit of memory shuffling, its very obvious when its genuinely done
Do you still think A40 is good download speed wise? I am still new to all this stuff so dont know which ru pod has the best download speed. Can only afford the .44cents-.80cents per hour pods

Absolutely, just not the community cloud stuff
If it was secure cloud you had an unlucky pod since I got 600mb/s when I tested
It's so weird lol. The first time I used the runpod with a normal template in kobold ai it worked fine.
But just in case the runpod http proxy fails (Rarely happens but sometimes they have an outtage) we have those backup links
I assume you used a model that fit the first time
The last time you just shut it down right before it was done
Was literally 1 minute away from working
Yeah, it was hard to tell if it was going to chug forever back then XD
It was copying to the first GPU when you closed it
The loading is pretty quick, its just that it didn't seem that way because your download speeds didn't go above 80mb/s and even dropped to 30 at points
The sweden and canada datacenters give me good speeds if you want to force it
Got it, thanks! I will try again later. Will let you know if I have some more trouble.
Hopefully I am online at the time since I built that template
Otherwise https;//koboldai.org/discord has an active help channel
Same link the template pointed you to when it crashed the first time