ostree-finalize-staged fails with SELinux error
remember this blast from the past?
I originally had that problem on my Bazzite rig... which I've let go idle (it dual boots) because I couldn't solve and seems I need to reinstall.
But now... I've run into it on a uCore(bOS) system! 😦
422 Replies
@M2 we should probably thread this as I'm now more motivated to try to understand this... it shouldn't be happening
Yay....
1) i really want a want to recover when this happens
Again for mine it was due to SELinux labels no longer existing in a new image
2) i'd like to prevent it from happening... and so far, it's been on my boS images, so i guess I stopped installing something which had installed SElinux label configs ?
Likely. For me specifically the cause was the following.
I had swtpm installed. I then mutated the file itself to fix the SELinux label.
Then I tried to remove swtpm from my image, but it couldnt finalize the deployment
I then readded swtpm back to the image and that seemed to fix it
I haven't removed swtpm since
I suppose this is one of the things composefs is likely trying to fix.
I also haven't had this happen since I started rechunking my images, but again my problem package of swtpm has been on every single image of mine since then
hmm... I'm rechunking, so I don't think that helps
ugh, once again, it doesn't tell me why
just bringing this link here for easy reference: https://discussion.fedoraproject.org/t/ostree-finalize-staged-fails-with-an-selinux-error/97734/8
My reading of this is that it's something to do with /usr/etc merge
i got busy with work, but thanks for that link too... i'm going to have to crack this nut eventually
i too have come across this.
oddly enough its with my ucore image. one system updated to that image with no problem, the other did not..
gives some output
to much to paste in here
good, we've both hit it on ucore and i've hit it on bazzite and m2 hit it on bluefin, so it's generic to ostree/container-navtive probably
and I realized I have this happening on a VM, so i've cloned the disk and I'm going to use that as a place to test/troubleshoot in a retryable manner
ya definitely an odd error
oh, that's interesting
granted those steps didnt shit, just posting what i am finding
and of course this is happening on my supermicro board system.. so reboots are slllooooooooooooww
rpm -V selinux-policy selinux-policy-targeted
shows a ton of missing policies
eh nevermind, same as on my system that is ok. hmm
GitHub
GitHub - hhd-dev/rechunk
Contribute to hhd-dev/rechunk development by creating an account on GitHub.
maybe something with the rechunking that is causing this?
interesting, second system is now doing it as well.
M2 had a situation where he thought rechunking actually HELPED the problem
On my test VM, I just attempted a
bootc update rebooted and got the error. Reverted to a snapshot I took specifically to be able to restore to the broken state and...
Yes. I can reproduce the issue with a revert.
This is all the time I can give at this moment. but it's progress to not just have a place to try to fix, but also being to reproduce.@jmac are you rechunking your ucore image?
i was, i just disabled it in hopes of it offering a solution
so one one server with issues
i reverted to an old build
and just updated
that server is fixed
hmm i cannot for the life of me get the other system fixed though
ok i was able to get the other server up. i rolledback again and that seemed to work
really odd
im going to setup a vm to see if i can repeat this
going to reenable rechunking on my builds and see what happens
i cannot get it to error out again
Yeah. That’s why I got a reproducible place for the big.
I’ve got. Some time to test today.
I’ll try disabling rechunkkng also
i cant say for sure if that is what fixed my issue
like i said, i rolledback and snagged a newer version
both seemed to be stuck on an early march version, so who knows how long the issue was persisting prior to me noticing i didnt have an update
i only found it because i was trying to get the 389 package in and ran across the issue.
i can't seem to even build my images when i disable rechunker
there's a lot of stuff going on in the Justfile which seems dependent on previous steps
You shouldn't need the rechunker. But if you are not using the rechunker, you need to not use the load images step
And not build the images as root
I'm assuming you are using my justfile
Yep. I figured out the not using rechunker or load images steps
It took me a while to realize to not use root
Then I still think there was a bug but I updated from you latest Justfile changes. I think it’s better. Need to go verify my test
Nope I get this error https://github.com/bsherman/bos/actions/runs/14048060735/job/39333054037#step:7:1
error: Recipe
get-tags could not be run because of an IO error while trying to create a temporary directory or write a file to that directory: Permission denied (os error 13) at path "/run/user/1001/just/just-dd8nhV"
Maybe I’m still doing sudo/root in the workflow
I would definitely say so
been working on this in between other things today splitting focus is not my strong suit 🙂
@M2 why this?
https://github.com/bsherman/bos/blob/main/Justfile#L185-L189
that seems odd
Oh I would remove the base image after building. Thoughts were to always pull the base image for builds + on the github action remove the base image once the build was complete
so that there would be space for rechunk
You'll also notice that the unrechunked image is removed here
https://github.com/bsherman/bos/blob/c612b7436deae17c265a766044236f887e4c2fbc/Justfile#L250
after you create the tree
right, but if I'm not rechunking...
If you're not rechunking.... then removing the base image doesn't really do anything
right
it removes the ref. But your build is just another layer on top of it, so removing it does nothing since your local image is built on top
i got a a green build now, i'm good
bleh, no... it doesn't push
https://github.com/bsherman/bos/actions/runs/14048743564/job/39335032959#step:6:90
You only tag the build with the name and not the name + version.
GitHub
bOS Build Server · bsherman/bos@c612b74
Customized OS images based on Universal Blue. Contribute to bsherman/bos development by creating an account on GitHub.
You probably should generate the tags and tag your original build with all of the tags
https://github.com/ublue-os/main/pull/770/files
This does that for main
GitHub
chore: cleanup justfile by m2Giles · Pull Request #770 · ublue-os...
Gets this working again. Does not have an ISO builder yet as we are between several options right now. This also has most of the stuff necessary to convert the github workflow to use the justfile f...
sorry, i didn'g get these notifications, but i've got it working i realized what was missing
i was trying to minimize changes so i could easily switch back to rechunking
ok, so rechunked images are definitely smaller
but whatever
for my personal use
now to see if my ostree-selinux issue is resolved by not rechunking
nope removal of rechunker did NOT fix it
and rolling back to an image from december 31 and then upgrading... does not fix
how did you see this?
when you say this "reverted" did you "upgrade" (rpm-ostree rebase/bootc switch) to an old image, or just do a rollback?
i'm digging into the C code for ostree finalize-staged/sysroot-deploy
under the hood, it seems to be doing a bwrap exec of
semodule -N --refresh in the staged ostree dir
hmm... come to think of it, i think i'm in the wrong section of code
yeah, what i'm seeing we aren't even hitting yet
ok, yeah this looks more correct...
it tries to do an ostree_sepolicy_restorecon
this will only last a day, but it's a diff of the changes i'm trying to apply, nothing stands out to me in removed package list
https://paste.centos.org/view/90e491a7
@Kyle Gospo just for context of what I was telling you about on our call the other night, this is the issue I'm trying to solve on a work VM server running ucore and on my bazzite desktop
I did just re read https://discussion.fedoraproject.org/t/ostree-finalize-staged-fails-with-an-selinux-error/97734/4 and the solution to Jean-Baptiste's issue was rebasing to upstream (sericea in his case) then back to custom image.
So... I'm going to try that. well, something like that.
no dice, i can't even go back to upstream coreos
I tried setting up bwrap to enter the staged deployment dir
but i am a bit lost, i end up in a context where sestatus thinks that selinux is disabled, so I can't even try to restorecon etc
and this is where i landed in the C code https://github.com/ostreedev/ostree/blob/4154366766fc910f54f4be5b0d816deaaade2379/src/libostree/ostree-sepolicy.c#L614 but not really getting anywhere
hmm... same thing if i do a naive chroot, something is odd, and i'm missing it
oh!
this ucore system has composefs
is that significant?
no wonder things seem a bit different than last time i dug deep
/me sigh
i was hoping that disabling composefs might at least change behavior... but noi heard selinux so I popped in, but it seems yall are in deep
at any point did you have an AVC
if there is an AVC, it happens at shutdown and is not logged... but i can manually run the finalize operation and don't get one
see this output for what i get
https://discord.com/channels/1072614816579063828/1352341718942482615/1352349176775839746
not loggedit should be written to disk and readable on next boot? hmm did you have anything layered also what triggered the issue or do we not know that yet
also was this happening before policy 41.33

yep, I understand. I don't think one is happening... Based on reading the ostree code, and M2's experience, I think that there's a missing label, and it's trying to relable/restore contexts, and it fails.
no idea
I can boot to my bazzite machine to check but i'm sure it's not going to have the same versions of that package changing
right
i can reproduce this in that i have a VM disk image with a snapshot I pulled out of my work server
i guess im more asking, when did this first start occurring
so even if we destroy the disk or fix it
because there are a lot of selinux package changes in that diff
I personally first saw it on my bazzite image end of January/early Feb
also a massive ostree upgrade
ah okay nvm
and that was getting updated weekly
wait, is this related?
this VM's uCore... i just updated a few days ago after a few months with no update... (last successful update was december 31
that's on Jmcgee's ucore instance
I don't know if/how it's related
it would be confusing because that avc is pointing to a var_run_t file
whereas your code link points to libostree/ostree-sepolicy.c
which would be unrelated
yeah, i'm not sure that's related at all
and i never had an avc on bazzite or my ucore instance
his is a getattr
whereas if this is happening in ostree_sepolicy_restorecon
it'd be a
relabeloh and another answer to you... i don't layer locally... i'm big time against that 🙂 thus custom images
do you have the full stacktrace
right, this is where i suspect it's happening, but i'm not sure
ostree_sepolicy_restorecon is a helper function
no stack trace, I haven't been able to get any more logs
would be good to know what parameters it was called with
damn
let me check all the invocations
if i had strace, i thought i could run that, but it's not on the machine, maybe I could install live
isn't it already borked 🫠
yeah, i can't hurt it, i can always rollback to the snapshot
could you curl a portable strace?
to be safe
that'd work too
but, i think it's installing fine
hard to hurt it more 😉
also that was from this, right
this is a manual run
where is the ostree-sepolicy.c
from
the line number you had
that's more or less what happens on shutdown
asking cause ostree_sepolicy_restorecon isn't called inside ostree
i was just searching the code to try to find stuff related,
so it must be called by rpm-ostree or bootc?
oh i see
your error message says
semodule failed which could involve changing contexts but sounds more like it's trying to install a policy file and that's failing
ah it's both
i see
yeah
some filecon in some module
:thonk:every other reference i can find to this online (including M2's experience) there's a file and/or package referenced in that output
but not in mine
eg https://discussion.fedoraproject.org/t/ostree-finalize-staged-fails-with-an-selinux-error/97734/4
yeah yours is different in that these errors are unrelated to ostree @bsherman
these are strings from selinux
yep
we need like
1 hint
😅
i know
these error logs are not helpful
this is why i'm going crazy trying to figure ANYTHING out
"something is wrong"
i abandoned my bazzite install, though I haven't wiped and reinstalled because I just didn't have the energy
when you first saw this in january, was it identical
but when this issue popped up here... now i'm concerned
also, you never rebase between ucore and ublue, right?
i think so, there's some history of my chats in #💾ublue-dev
that's heresy, my friend
lol yeah just making sure
do you have the exact log
like
this
with a timestamp
sure
well, no
sorry
when this happens on shutdown that doesn't even get logged, i'll provide a fresh example in a moment
that message only shows when running manually
so, here's current state:
I'll reboot now.
hmmm
https://forums.almalinux.org/t/dnf-upgrade-problem-with-selinux-policy-targeted-38-1-11-2-el9-2-on-amavis-new/2428
a quote from this page...
So yeah, this aligns with your comment about it looks like an rpm install failing
can you post the diff
db diff
i want to see what those upgrades are
it's what was in the pastebin
wait but that selinux-policy is ancient
ah okay
i know, it's just an example of the same error messages
it could be one of the commits between 41.26 and 41.33
hmm...
without knowing which of these it is though, it's just guesswork
Problems processing filecon rulesGitHub
Update the bootupd policy · fedora-selinux/selinux-policy@d307fa8
In particular, the following permissions were allowed:
- allow read files in /sysroot, which have root_t type
- allow read udev pid files in case lsblk was executed from bootupd
so no transition ...
there are months of commits between those versions
so... i could try upgrading to a specific version much closer to the date of the current deployed image
wdym
version of?
the oci image that's deployed is from December 31
ah
i could try
bootc switch to an image that's only a week after
for exampleyes
i suspect that would work
41.33 shipped in february
if that works, it would at least give some weight to the theory
ok,
and then
oh yeah, so it does have the timestamp 😄
i'll try it, no reason not to
which stamp
oh you mean 12-31
yeah
if you can, try upgrading one selinux policy version at a time
from here to 41.27, then 41.28, etc
until it breaks
if it is that package, that will narrow it down a lot
yeah, i'l just going to the earliest image i can find for now
kk
really hoping at least the first one doesn't break
no selinux changes in that diff
Thank you for coming to look at this with me 🙂
and identical error?
damn.
well
that rules that out
:/
what is in that diff
Even if we don't solve it ... it's nice to have someone else's perspective
it worked!
⁉️
what worked!?
i thought it broke!?
what is this
⁉️
‼️
😛
that's the output from the last attempt to do an update to current image version
ohhh
previous deployment
this is the status after
bootc switch ghcr.io/bsherman/bos:ucore-minimal-20250109okay okay
okay
so we're in business
and there was no selinux package change
so
and you booted into it okay okay
yep
bootc switch but dont reboot until the selinux-policy package upgrades
maybe 1-2 days at a time?
so it's at least possible now that the problem is the selinux-policy package itself
good idea
selinux-policy 41.27 shipped in december
i have weekly builds, so i'll try this and call out when i have a diff
shouldn't have taken too long to get through the pipeline
kk
yep
if we can narrow it down to a specific version we can probably ID the commit
yep
found it
selinux-policy-targeted 41.26-1.fc41 -> 41.27-1.fc41
rebooting on this image update
ostree finalize and reboot successahh shit
time for the next one
yep
but hey, this is progress
also
this is NOT possible on traditional distro 🙂
i'm amazed this can be done!
can you tell i've used this method before 😛
lol
selinux-policy-targeted 41.27-1.fc41 -> 41.28-1.fc41
🧑🔬
great success?
reboot success
getting closer to the bad one...
yep
theoretical bad one at least
what if we get to latest and it works 🫠
it's possible
i wonder too if there might be a scenario where if upgraded in sequence there's no problem, but you can't make a big leap
that there was some policy change that assumes some file exists or something
yup
still though
that shouldn't matter *in theory
i think 41.29 is the one that will break
@bsherman this may be it
I made some more investigations, and reported https://bugzilla.redhat.com/show_bug.cgi?id=2342260. This really is specific to updating selinux-policy together with some other foo-selinux in the same dnf run. Updating separately works. The observable difference other than the "policy rejections" is that "semodule -l" has an additional "extra_binsbin" policy in the broken case.wait this explains it perfectly tbh selinux-policy is probably not aware of policy changes made by other packages so then the new FCs clash
oh?
but they don't if the DB already contains them
where is this quote from ?
FEDORA-2025-e7a319968a
—
bugfix update for selinux-poli...
management of Fedora Project updates
let's see
seems very plausible
yeah, i'm booting the bazzite to check versions there
considering it's literally a case of "you waited to long to upgrade and now you have multiple selinux packages upgrading at the same time"
versions on disk or in the db?
yes
it would need to be selinux-policy + some other *-selinux package in the db diff
but
i dont want to jump to conclusions too soon
ok here(still on the ucore instance) i have an selinux change but a diferent package
so rebooting for that one
this and an selinux change?
selinux-policy
or just that one
that was the only selinux reference in the diff
OK, rebooting for these updates
woah
that's a big jump
fail
i'm going to backup a week
were there any other policy changes in that diff
or just those
time to look at some commits 🔍
i think just those
hm okay scratch my previous theory
can you post the full db diff for my sanity
ok, paste bin with full diff as I don't trust my eyes right now (you messaged before i could finish typing the same thing)
https://paste.centos.org/view/72e1f47c
and reboot on that fails to finalize
the error is identical right
about filecons
yes
candidate commits (with fc changes):
- https://github.com/fedora-selinux/selinux-policy/commit/3314785460528c93f61de3bf032ece6d85e71b49
- https://github.com/fedora-selinux/selinux-policy/commit/fc05cc87d6c60206257940ef02376adc03cc8fb2
- https://github.com/fedora-selinux/selinux-policy/commit/7a19b319a1e9809c0765282a2eb06496c711a2de
- https://github.com/fedora-selinux/selinux-policy/commit/36e325960ba98edd13d5776b86bb4639f918862a
- https://github.com/fedora-selinux/selinux-policy/commit/72752d81857b85395d1d6b9822458b4ed9a649fa
- https://github.com/fedora-selinux/selinux-policy/commit/a3a297010c51eb4d8f1c4d446ed3712eaf344217
this one is interesting https://github.com/fedora-selinux/selinux-policy/commit/7a19b319a1e9809c0765282a2eb06496c711a2de
GitHub
Label /usr/bin/dnf5 with rpm_exec_t · fedora-selinux/selinux-polic...
Unlike dnf 3, which uses the /usr/bin/dnf-3 as a filename,
dnf 5 started to use /usr/bin/dnf5. dnf 4 is just a symlink.
The file context pattern was simplified.
Additionally, /usr/lib/sysimage/dnf...
wtf is rpm-sequoia
And here's the current Bazzite install (from Feb 04) and it's next available update from Feb 09
nvm, unrelated librpm_sequoia
wait
so one failed going from 28 -> 31
similar, but not same version changes
yep
one from 28 -> 32?
yep
hold up
that eliminates some candidates
we are looking at 29, 30, 31, but not 32
yep
down to 6
this still assumes this is the package at fault
it's a reasonable assumption but still an assumption
yeah
wait okay it's almost certainly not this one https://github.com/fedora-selinux/selinux-policy/commit/72752d81857b85395d1d6b9822458b4ed9a649fa
GitHub
contrib/thumb: fix thunar thumbnailer (rhbz#2315893) · fedora-seli...
For thunar, the path is ~/.local/share/thumbnails.
yep
this is just adding another homedir for thumbs
probably not switcheroo-control either?
🤷♂️
and the kerberos one just removes regex syntax
https://github.com/fedora-selinux/selinux-policy/commit/fc05cc87d6c60206257940ef02376adc03cc8fb2
https://github.com/fedora-selinux/selinux-policy/commit/7a19b319a1e9809c0765282a2eb06496c711a2de
https://github.com/fedora-selinux/selinux-policy/commit/a3a297010c51eb4d8f1c4d446ed3712eaf344217
GitHub
Label /dev/pmem[0-9]+ with fixed_disk_device_t · fedora-selinux/se...
Non-Volatile Dual In-line Memory Modules (NVDIMM) is a persistent memory
technology which combines the durability of storage with the low access
latency and the high bandwidth of dynamic RAM. In th...
GitHub
Label /usr/bin/dnf5 with rpm_exec_t · fedora-selinux/selinux-polic...
Unlike dnf 3, which uses the /usr/bin/dnf-3 as a filename,
dnf 5 started to use /usr/bin/dnf5. dnf 4 is just a symlink.
The file context pattern was simplified.
Additionally, /usr/lib/sysimage/dnf...
GitHub
Label /dev/iio:device[0-9]+ devices · fedora-selinux/selinux-polic...
The Industrial I/O core offers a way for continuous data capture based
on a trigger source. Multiple data channels can be read at once from
/dev/iio:deviceX character device node, thus reducing the...
one of these three imo
confirmed that Bazzite failed the ostree finalize staged with this diff
dnf one is still interesting
same filecon error?
yes, same error
the weird thing is
if this is really a policy issue
why is it only happening on some hardware
right?
right, i use the same build process for my bluefin image, but it never had a problem updating
i wonder if it has something to do with the availability of these hardware devices
i think the bazzite update happens to include that massive changeover Kyle did in Feb
can you
ls -lZ /dev/iiohmm... well, the VM has very little available hardware
oh vm
yeah..
my laptop and desktop have much more in common
hmmm
same for pmem
?
yeah
idk why the dnf one would be an issue...
does ostree use libdnf
oh....
bootc does, right?
i think bootc does yes,a nd thus rpm-ostree under the hood now
yeah that's expected prior to this upgrade
i wonder if
either
so that policy needs to change those labels
1. bootc/rpm-ostree fucks with the policy for those dirs in some way
or
there needs to be a relabel
2. changing the filecon for libs in-use is causing issues
when you upgrade, are you using bootc or rpm-ostree, or both
my bluefin
yeah i have this too
i haven't specifically tested with both, but mostly i've been doing bootc update/switch
can you try with rpm-ostree upgrade or rpm-ostree rebase for sanity
if it fails the same way, then it's unrelated
but if it doesn't then there's some bootc issue with libdnf
and i wonder if others didn't see this issue because rpm-ostreed just upgraded in the background without bootc
it worked??
that would be plausible
it failed the same way
aw
where's the fail
oh
on reboot
right
ok scratch that
yep, on reboot
all my theories 😔
i am at least validated that having this VM for testing is much easier than a full bazzite desktop
so much faster to iterate
and our set of changes can be narrowed somewhat
wait when you say fails at reboot
do you mean as it's shutting down
or as it's booting up the next time
also are these both custom images
and if so, can you link me the repo
i have a new (probably shitty) theory
the journal entry i keep sharing different versions of... i believe that comes from the ostree-finalize-staged.service which runs at host shutdown when there is a pending deployment
yes, custom images, all from same repo in fact
link pls
i now suspect it's one of your layered packages
cloud layered
i saw nfs-utils and got spooked
that package has caused me nightmares
oh?
nfs-utils is in ucore
upstream of my custom
yeah nvm
it's only on your server image anyhow
wait a fuckin sec
cockpit-selinux
well, it's on bazzite too
ah
i think maybe pulled in by libvirt stuff?
i assume you already confirmed that rebasing to "plain bazzite" works?
nope
that would be good to check
because rebasing to "plain coreos" does not work
at least, not current stable
plain coreos meaning fedora's or ucore
both
both fail in the same manner as we've seen
oh
i could try rebasing to a ucore that's closer to this timestamp than my custom
maybe get smaller incremental changes
this is so far the most perplexing part
it's one thing if it's something you're adding that isn't in a common install
but if it repros on an official image
with like 350 packages
ok i'm rebasing from my bos:ucore-minimal 20250302 to ucore-minimal-20250302
then it's not something you're doing
alright
im just bummed because this means i can throw that theory out the window
it doesn't make sense though
other people aren't seeing this
how is it not a package you're adding
:thonk:
my assumption (based on other's experiences like M2) has always been i've got a file with a label in a place not expected and when the policy changes and that label no longer exists, the relabel fails some how
but we would see that label disappearing in the policy commits no?
true
wait also
but this was M2's original experience, he removed a package which provided a policy
you're not using some unique filesystems or anything right?
xfs
stock
xfs 👀
that's CoreOS standard
oh
bazzite is btrfs
when did that change
it's always been that way
CoreOS has never defaulted to btrfs
one of the reasons we tell people not to rebase across 😄
reboot successful with this.
i'm going to move forward incrementally
oh i see yeah nvm it is xfs
ucore-minimal doesn't have cockpit stuff right?
not as much
it has
hmm
even further upstream would be even better to eliminate more variables
but this is fine i guess
there's a coreos-bootc image on quay right
yes, but also
quay.io/fedora/fedora-coreos:stable which is what we base onah yeah
that works
but i feel like there's something going on with the "custom" images
you already verified it repros on fedora coreos though
because no one has reported this before ... just me, jmac, m2
the issue repros
that was my theory too but you said you can repro on upstream
when attempting to switch to latest stable image, yes
damn
yeah, but from a custom
wait
wait
yeah
ok, here's the interesting ucore update
rebase from custom:oldtag -> noncustom:oldtag
then noncustom:oldtag -> noncustom:latest
https://paste.centos.org/view/bc182d82
this one has the selinux policy jumps
and it failed?
and it WORKED
ah okay
yeah
so now...
you did this?
i bet i can go backto my custom and be good
yes but if you go back to oldtag on custom it will repro i think
what did you do exactly
what path was followed
custom:oldtag > custom:latest | fails
----
custom:oldtag > noncustom:oldtag | works
noncustom:oldtag > noncustom:newerbutnotlatest | works
this is where we are now
yep makes sense
so some change on custom breaks it
right
ima try rebasing bazzite to something oldtag
wait hold up
ok
do you still have the db diff from custom:oldtag > noncustom:oldtag | works
or is that gone
hold
wait a sec
could it be because you removed a file that had its context changed?
🙂
that should be conditional
it's at the top of build.sh
one moment
Unlike dnf 3, which uses the /usr/bin/dnf-3 as a filename, dnf 5 started to use /usr/bin/dnf5. dnf 4 is just a symlink. The file context pattern was simplified. Additionally, /usr/lib/sysimage/dnf and /usr/lib/sysimage/libdnf5 were labeled with rpm_var_lib_t, similar to /usr/lib/sysimage/rpm.https://github.com/fedora-selinux/selinux-policy/commit/7a19b319a1e9809c0765282a2eb06496c711a2de 95% sure this is it
https://paste.centos.org/view/f0fcf81f - custom:old > noncustom:old WORKS
rm'ing that bin corrupted the selinux db i believe
yes, but
hmm
that's happening (or was happening) in all the ublue image builds
and you're sure that dir wouldn't exist at that time
m2os and I tested that before putting it into bluefin/main/bazzite, etc
i see
that dir only exists at buildtime if rpm-ostree wrap was used
it MIGHT be the issue
do the build logs for your build from 0305 still exist
i'm not sure
if that log is in there
lets look
then we can rule it out
https://github.com/bsherman/bos/actions/runs/13670135659/job/38218624134
i think upstream had already made that change
but
echo is absent though :thonk:ah!
yep and no
-x
you are right
it ran that there
ok
so... now, that i'm on that same version of policyOMG that's it
what did you confirm
what am i looking at here
oh
it's there
i see
so... this shows that my current system is March09
yeah
yup
and the rpm-ostree/wrapped is present
BUT
this also has the new policy stuff
right
well
so, now... if i go back,
march 6th but yeah
back to custom image, should work
i think
lol
to the latest on the custom image?
rpm-ostree wrapped was cursed from day one
uhh
i hated that
the issue here is
rming binaries that selinux is aware of 😅
you should remove those rms 😛
it will make selinux angrywell, i dunno
you CAN rm a file
it's fine
also
rming files provided by an rpm is kind of cursed anyhowthere's something else in play
wdym
they weren't though
dnf is
and selinux is trying to relabel it
because the filecon changed
right?
but the file is removed
so it fails?
rpm-ostree wrap literally created a directory
/usr/libexec/rpm-ostree/wrapped/ and moved the rpm files into it...
replacing them with stubs
my script just undoes that mess and tries to put things back the way rpm wanted it
that's why i say it was cursedbut
did the wrapped stubs have the right filecontext
i think the issue might be
you need to restorecon after you mv -f
actually can you check the filecon on the cliwrapped versions
i think this is probably the case...
oh you did
look here
they're bin_t
yeah that's the issue
yep
so this IS probably a global ublue issue for any image which is still using this ... and we can test it
im not entirely sure it's the issue tbf because dnf itself didn't have its label changed
but
dnf5 didyeah, but we can still test it
wait.. then why is no one else seeing this
first, i'm switching back to my custom image from non-custom:0309 to custom:0309
make sure this works
i think there was a small window where this was happening
at least in upstreams like bluefin/bazzite/main
the test will be... rollback my VM to known "bad" old custom
rebuild my custom image with a restorecon added in after the mv
see if upgrade works
welllll
but the issue might be in the old image
that's the thing
yeah, that's the concern
like it might be the label going from wrong -> right
but, even if... at least we have a workaround
right
find the point where this occurs, and rebase to that on upstream, upgrade, then switch back to custom
but i was LOST before
you have helped SO Much
no prob
i still think we dont fully have a root cause
because the change in the policy is on dnf5
not dnf
but also dnf5 is modified in that script
:thonk:
i'm installing dnf5
there's something more at play here
right...
ok,
test VM is on custom:latest
success
or maybe the modification to dnf triggers selinux to relabel the whole dir or something
essentially following the workaround solution
ok, so it looks like my latest build is still doing manual rpm-ostree unwrap
https://github.com/bsherman/bos/actions/runs/14049430082/job/39336910290#step:6:169
doing another build with -x to verify https://github.com/bsherman/bos/actions/runs/14052705620/job/39345858075
and then i'll add restorecon
and then try to upgrade from :oldtag to the new build?
exactly
hopefully that works but if it doesn't you're kinda SOL still because
there are too many moving variables
well, at least i won't be creating possibly bad images, and we'll know if we CAN restorecon
restorecon should also spit out info into the build logs if it's doing something relevant
i suspect it'll work though
since this is happening on the finalize step
i think it was just a matter of time until someone touched the selinux policy for dnf
and once that happened, this bug was bound to surface
that combined with for some reason this script is running despite the cliwrap stuff having supposed to have been removed
hmm

🙂
not really a swiss cheese model tbh
but
¯\_(ツ)_/¯
https://github.com/bsherman/bos/actions/runs/14052705620/job/39345858075#step:6:179 we have logging of it moving
this bug has been very de-motivating for me 🙂
sometimes problems are good challenges ... sometimes they sit in the back of your mind and haunt you
yup
and it didn't help i just didn't feel I had the time to sit down and tackle it for over a month
but when it popped up end of last week on a work server ... i was very concerned... because my gaming rig, ok, maybe I fiddled once and forgot
but i don't fiddle with the work server 😄
when in doubt, i made selinux angry somehow
it's always angry 😔
I am slowly learning
ive been writing policies for confining Trivalent
very fun
🫠
for so long i just turned it off
let's just say, the interfaces fedora provides are very useful
but i refused to do that from day one with ublue... before i even realized it could be very very bad to do so LOL
such as? 😄
LOL
Every time you run setenforce 0, you make Dan Walsh weep.
https://github.com/secureblue/secureblue/blob/live/files/scripts/selinux/trivalent/trivalent.te#L166
so many interfaces
so... many...
😵💫
chromium-based browsers need access to so much shit
it's crazy
but why
hmmm....
and yet it needs it
also pretty much everything in userspace is unconfined...
so
sad
the hell?
can you rebase and check if the label changed
if it didnt
then there goes that theory
🫠
testing an upgrade from custom:old to that custom:new image
i now expect failure 😭
and my expectation was correct
rats
but also
GitHub
fix: should restorecon /usr/bin after un-cliwrap · bsherman/bos@f0...
Customized OS images based on Universal Blue. Contribute to bsherman/bos development by creating an account on GitHub.
bazzite does not run this code, at least not today
so now we're back to
"it's something custom, but not dnf"
no
ok that puts the nail on that one
i think it could still be this thing
?
how so
if bazzite isn't touching dnf
if the old image is wrong?
today
what about a month and ahalf ago
im lost
oh
you mean like
in the past if bazzite was tampering with dnf
well, damn
https://github.com/bsherman/bos/actions/runs/13223254675/job/36910884181#step:6:168 bazzite didn't have cliwrap here on 0209
but it DID on the last image I can update to https://github.com/bsherman/bos/actions/runs/13146338233/job/36685198902#step:6:174 0204
^^?
aha
so
well wait
0209 is what your machine is on right?
oh
bazzite and ucore have different dates
maybe the tampered filecon persisted
can you check the filecon for /usr/bin/dnf on the bazzite machine
yeah, so that's kinda my thought... if the old image has bad filecon
if it's bin_t that all but confirms it
then even a good new image can't handle updating bad label and migrating policy at the same time?
Version: bazzite-nvidia-41.20250204.3 (2025-02-04T22:59:14Z)
that im not exactly sure about but selinux tends to shit itself at the slightest db corruption
that's why any
rm /usr/bin/* makes me quake in my boots
not worth the risk of selinux db corruptionit's not exactly a solid theory
but
yeah we haven't confirmed it
but also
it's not ruled out exactly
its a plausible hypothesis maybe, with a workaround for the bug
yeah
it'd be nice to confirm it
do you have a time machine
let me check
this thread
pretty much
i'm just super, super happy to have a workaround
i'm going to test the bazzite update now
sweet
let me know how it goes
sudo bootc switch ghcr.io/ublue-os/bazzite-gnome-nvidia:stable-41.20250127 in the works
bazzite on desktop, so much slower to test than VM with ucore 😄
so while waiting for that real hardware to do things...
ucore test reproduced the workaround solution:
from ucore-minimal-custom:stable-20250209
bootc switch ghcr.io/ublue-os/ucore-minimal:stable-20250209
# reboot
bootc switch ghcr.io/ublue-os/ucore-minimal
#reboot
should now be on current ucore-minimal no problems
bootc switch ghcr.io/mycustom/ucore-minimal-custom:stable
#reboot
should now be on current custom ucore-minimal no problems
verified success
bazzite tested workaround solution:
from bazzite-custom:stable-20250204
bootc switch ghcr.io/ublue-os/bazzite-gnome-nvidia:stable-20250127
# reboot
bootc switch ghcr.io/ublue-os/bazzite-gnome-nvidia:stable
# reboot
should now be on current bazzite-gnome-nvidia no problems
bootc switch ghcr.io/mycustom/bazzite-custom:stable
# reboot
now be on current custom ucore-minimal no problems
see above, it worksCan you provide dates?
For stuff based on main in the past couple of months we removed cli-wrap from main images.
I also think this is different than my experience. But I'm now wondering if this bug is affecting more people and they simply don't know it
GitHub
chore: remove cliwrap and call dracut directly (#679) · ublue-os/m...
Co-authored-by: Kyle Gospodnetich
20 Feb.
This also would of only affected your Bazzite build.
And Ucore I believe has never used cli-wrap
did a rollback
When i get home i can check my history, i think i just found that in journald when checking auditd issues
looks like it got solved and explains why a rollback fixed it, from what i could gather from quickly perusing the history of last nights chat. 🙂
I think there are likely multi ways to reach the broken state. Example, I doubt Jean-Baptistse’s problem was tied to the un-cliwrap.
Dates are in thread. I can dig more closely.
I think the common factor is the upgrade of selinux-targeted-policy and the cli wrap stuff being on old image.
At least that’s the hunch.
We found other examples online where people hit the same basic error message when updating the package even on older Alma. So if something was out of whack, it could happen
In ucore, yeah I think we did/do cliwrap and as evidenced by my build logs.
And the timing of the issue on my server was waiting for an upgrade from an old image, but I could upgrade up until the date where that selinux policy package updated but not past it.
Similarly with Bazzite. When that package updated (incidentally during the big Bazzite stable upgrade in Feb which included removing cliwrap) that’s where I got stuck.
But the cli wrap stuff could be a red herring? However, it does correlate and matches a change in the selinux policy package And that package update definitely seems to be in play.
The failure seemed to come from a rpm upgrade’s post section failing on restorecon or something.
I feel like cli-wrap is a red herring.
I wonder if we've experienced different failure conditions
the main thing is it correlates with a policy change in the package which updated related to dnf paths, and my un-cliwrap script was mucking with those specific paths... but yeah, it's not conclusive
https://discord.com/channels/1072614816579063828/1352341718942482615/1353954043101446185
which is a quote from https://bodhi.fedoraproject.org/updates/FEDORA-2025-e7a319968a
indicates someone saw the same kind of problem elsewhere probably just in a dnf run, maybe not in an ostree context
just changes to
selinux-policy-targeted and some other foo-selinux in the same dnf run
and I narrowed down the problem to both ucore and bazzite updating from:
selinux-policy-targeted 41.26-1.fc41 to 41.31-1.fc41 and 41.32-1.fc41 respectively
while also upgrading selinux-policyit's definitely possible

GitHub
testCreateUrlSource fails in updates-testing due to SELinux rejecti...
The job fedora-41/updates-testing failed on commit 2c51415. Log: https://cockpit-logs.us-east-1.linodeobjects.com/pull-0-2c514156-20250118-020715-fedora-41-updates-testing/log.html
cockpit is still another potential culprit
@bsherman do your machines pull in freeipa-selinux
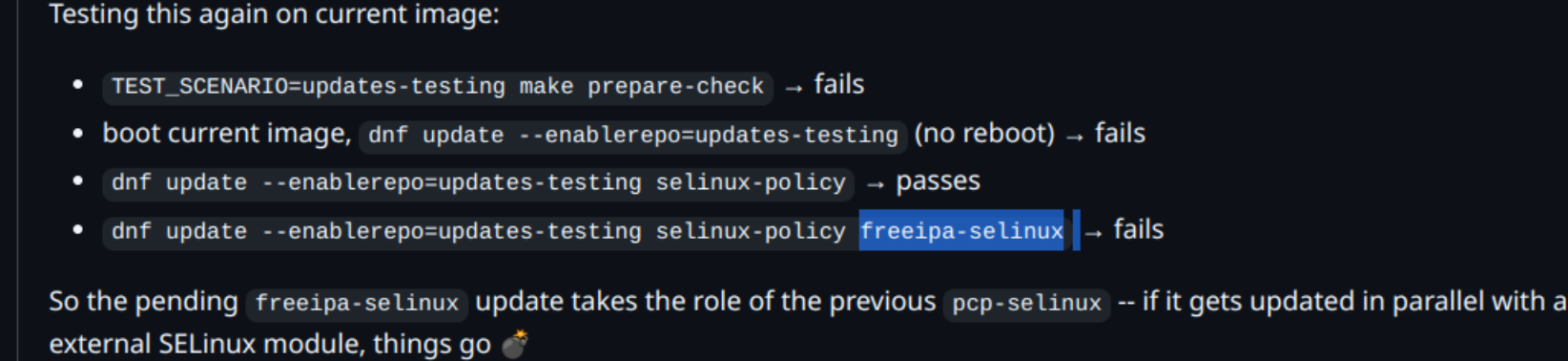
Another person ran into this.
This time it looks like semodule was missing?