Micro-optimizing a Z80 emulators' pipeline. **Unsafe code**
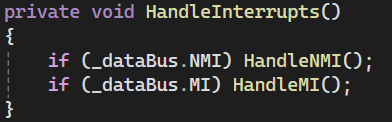
so, i'm writing an emulator, and i'm trying to squeeze as much perf as i can out of hot paths. this seemingly simple fetch operation consumes about a third of the CPU time:
my memory class looks like this:
i know, it's a bit messy, and it's not really safe either, but boy does it give some perf gains. it's worth it. also, the array wont change size so it should be alright.
my registers are in a similar situation. the register set is actually an array of bytes that are accessed using constant indexers into said array, like this:
but, this is a Z80, meaning it also has 16-bit register pairs. this is important, because you can either access it as its high and low parts, or its entire pair, meaning that the exposed pairs depend on this same array, so i implemented them using properties
with all of this in mind, how can i make that fetch instruction faster and use less CPU time?
my memory class looks like this:
i know, it's a bit messy, and it's not really safe either, but boy does it give some perf gains. it's worth it. also, the array wont change size so it should be alright.
my registers are in a similar situation. the register set is actually an array of bytes that are accessed using constant indexers into said array, like this:
but, this is a Z80, meaning it also has 16-bit register pairs. this is important, because you can either access it as its high and low parts, or its entire pair, meaning that the exposed pairs depend on this same array, so i implemented them using properties
with all of this in mind, how can i make that fetch instruction faster and use less CPU time?