EmberJson: High level JSON library
I've spent part of the last week on the beginnings of JSON library for Mojo. It's still very much under development so I haven't made any official releases, but if anyone would like to help add test cases or point out edge cases I've missed that would be greatly appreciated!
https://github.com/bgreni/EmberJson
A quick example of how it's used:
GitHub
GitHub - bgreni/EmberJson
Contribute to bgreni/EmberJson development by creating an account on GitHub.
43 Replies
Very cool! 😎
I wrote a similar parser a few weeks ago. Seems to be ~2.5 faster. https://github.com/phomola/mojolibs/tree/main/src/textkit
GitHub
mojolibs/src/textkit at main · phomola/mojolibs
Utils for Mojo. Contribute to phomola/mojolibs development by creating an account on GitHub.
How are you measuring?
I just ran your benchmarks.
Oh upon further reading I didn’t realize Unicode respects the same first 128 characters as ascii. I’ll try reading it from raw bytes as you’ve done and see where that gets me
Yes, I think reading from raw bytes is better here.
Your code should be faster then because I first tokenise the input.
Ah yes that has yielded quite the improvement, thank you for pointing that out!
Hi @bgreni cool library. Some comments on your approach:
I have a PR open which will make split more efficient and make StringSlice.split() return a List[StringSlice] so there is no allocation beyond building that list.
My next feature in line is doing something similar for splitlines so that you will have the option to have your Reader struct already have everything semi-tokenized very cheaply, because splitlines splits by every character except " " (which you dont want to split since your fields might have strings with whitespace). You can also implement your own version since we follow Python that also takes some newline separators into account that the JSON spec doesn't (AFAIK).
If you want to keep the peek approach, you can make it faster by going over a byte Span or using UnsafePointer since string slicing is expensive because it checks bounds and allocates one each time. You can look at the code in the split PR to take inspiration.
Mojo is very cool and you can make your const types be very readable:
Anyway GLHF! looking forward to a PR/review of one by you on this 🙂
string slicing allocates?
sorry meant to say why does it
yep since it returns a String instance which owns its data. Also it should be noted that it currently does not work by unicode codepoints and it will in the future, which will also add overhead
so overall using
StringSlice as much as possible and Span[Byte] as well are the best ways to go since they are non-owning types that just offer a view into the dataI would expect slicing a string to return a
StringSlicemaybe in the future, but currently it doesn't
Congrats @Martin Vuyk, you just advanced to level 5!
I've opened a proposal to change the way we do
__getitem__(self, slice: Slice) to return an Iterator instead of a new instance
We'll see where it goes, might get changed for something else 🤷♂️ . The whole stdlib is still WIPStringSlice is basically just a Span wrapper at this point, and Span doesn't work with strided steps at the moment, so expression like this currently require it to copy into a new String
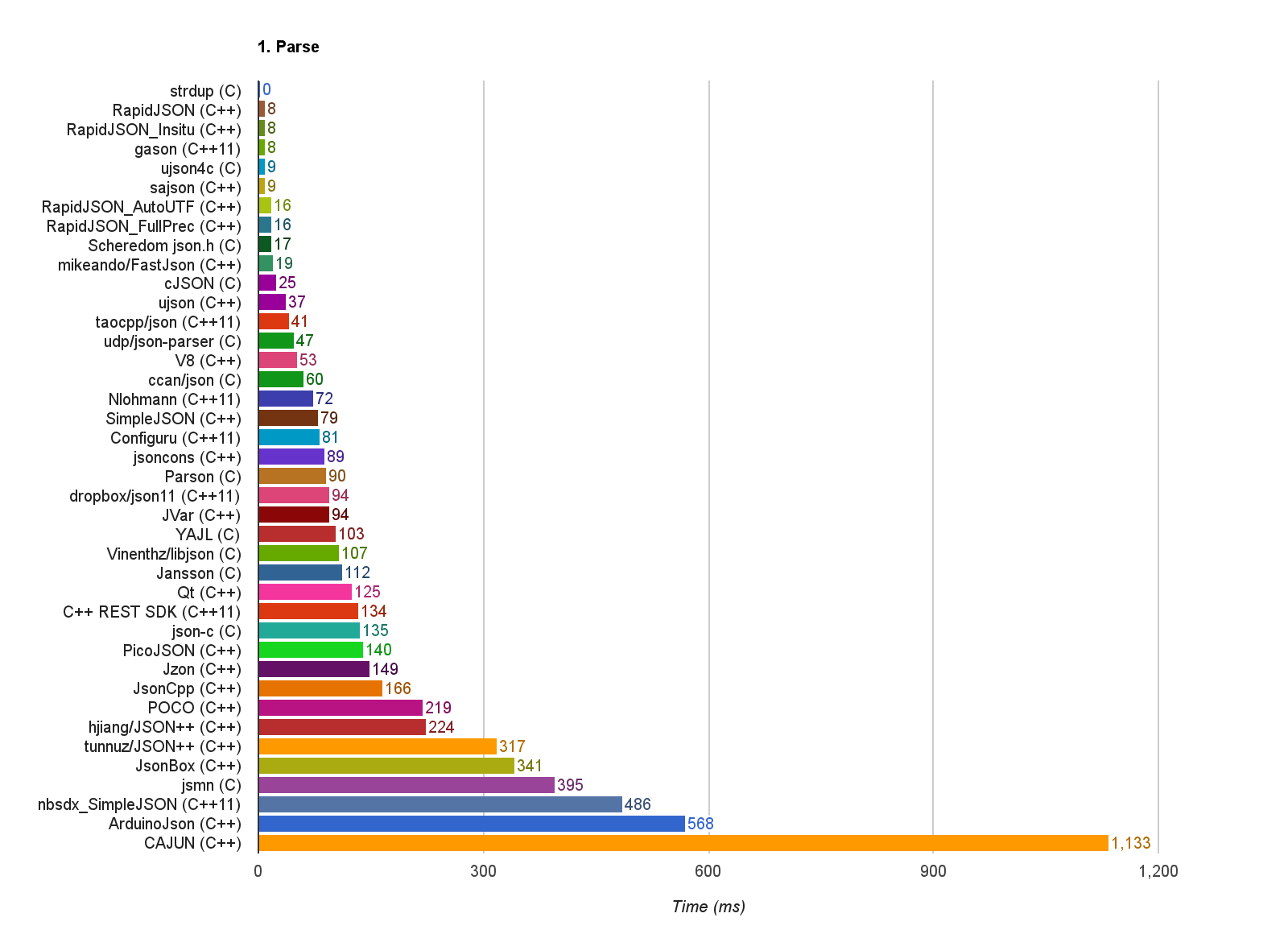
In case it's useful to anyone I found this collection of benchmarks and validation tests for json https://github.com/miloyip/nativejson-benchmark
I made a benchmark using these three big files it seems to be using for it's parsing performance section https://github.com/miloyip/nativejson-benchmark
I'm getting about 121ms which would put it at the top of the lower half of this graph? (Probably not since I'm using much newer hardware than what was used for this graph though)
GitHub
GitHub - miloyip/nativejson-benchmark: C/C++ JSON parser/generator ...
C/C++ JSON parser/generator benchmark. Contribute to miloyip/nativejson-benchmark development by creating an account on GitHub.
I've removed unnecessary heap allocations and now my parser seems to be faster again :)
Tag you're it lol
There's also a collection of conformance test cases in this repo which was very helpful https://github.com/miloyip/nativejson-benchmark/tree/master/data/jsonchecker
GitHub
nativejson-benchmark/data/jsonchecker at master · miloyip/nativejso...
C/C++ JSON parser/generator benchmark. Contribute to miloyip/nativejson-benchmark development by creating an account on GitHub.
@bgreni thanks for this, working well
was easy to add
from_listThank you! I think I’ll finally do an actual package release to prefix.dev tomorrow for nightly
could the return type be inferred here, down the road?
looking forward to comptime reflection
this could just be a loop
Infer the type where exactly?
Congrats @bgreni, you just advanced to level 4!
of the struct field
more a mojo question
I imagine probably not?
EmberJson has its first release on prefix.dev in the
mojo-community-nightly channel! https://prefix.dev/channels/mojo-community-nightly/packages/emberjsonprefix.dev
prefix.dev – solving software package management
The software package management platform for Python, C++, R, Rust and more
Hey! I also created an open-source project for JSON handling in Mojo: sonic-mojo. It seems to be ~7.5 faster than the parser you mentioned(https://github.com/bgreni/EmberJson)!
This project is based on Mojo FFI bindings for sonic-rs and uses Diplomat for code generation, with some modifications in my forked version f0cii/diplomat.
Here are my benchmark results:
https://github.com/f0cii/sonic-mojo
Very cool! I've just written it quickly from scratch so it is quite slow lol. I've thought about trying to port over the simdjson implementation, but that's a lot more time than I have right now https://github.com/simdjson/simdjson
GitHub
GitHub - simdjson/simdjson: Parsing gigabytes of JSON per second : ...
Parsing gigabytes of JSON per second : used by Facebook/Meta Velox, the Node.js runtime, ClickHouse, WatermelonDB, Apache Doris, Milvus, StarRocks - simdjson/simdjson
Hi @eggsquad I'm not sure it's the right place but I tried to add emberjson as dependency (from the nightly community channel) and
magic search fails to find it although it successfully finds other packages in the same nightly channel (and it resolves their latest versions).
But it finds others like mog, weave and huethats odd, I'll take a look, thanks for bringing this up!
@stano Seems to work for me now?
It does resolve now. The only change I mad was switching to max nightly, I believe.
I'm still getting my way around for stable vs nightly so I probably didn't realize the nightly community channel packages require nightly max (in this case >= 25.1).
I apologize for taking of your time
Ah yes I haven't made a stable version of the lib yet. No worries though thank you for trying the package!
Not sure if this really needs announcing but I am formally opening up EmberJson to contributions! https://github.com/bgreni/EmberJson/blob/main/CONTRIBUTING.md
Any thoughts on when it’ll make it to a version that works with stable max? 😄
I find it easier to development on nightly so honestly I was largely waiting for someone to ask lol. I'm currently looking at some changes to float string conversion but I can look into doing one afterwards?
No rush! Just curious. Was thinking about handling json payloads for the client in
lightbug_http 🙂EmberJson now has a stable channel release! Version 0.1.1 (because I botched my conda package in 0.1.0 lol) is available in the mojo-community prefix channel!
https://prefix.dev/channels/mojo-community/packages/emberjson
Also a somewhat notable addition I've added some support for unicode character decoding so stuff like this works now.
Hey @eggsquad, any interest in talking about this project at our upcoming community meeting on February 3rd?
Oh wow what an honour! Yeah I can do that
Awesome!
What kind of content should I be doing? And how long, etc?
Most folks create a couple slides to talk about the purpose of their project and then do a demo, but it's very open ended! You're welcome to as much time as you want, but the average presentation is probably ~15 minutes + Q&A
@bgreni Could you please DM me for a question I have regarding your and my talks on Monday? Can't DM you...