Why it seems like my job isn't assigned to a worker ( even after refreshing)
Read title


31 Replies
I think it should be assigned after a few secs? this has been 10 seconds++ and it hasnt been assigned
Also when i use this
the other jobs doesn't get assigned to to the workers
I'm experiencing the same thing right now
Oh on serverless?
What were you running
so you are sending requests to your endpoint and those are not picked up by workers?
Yes
took too long, the job finnally got picked up like after 2mins~ this once
So is the situation better now? Or is it still very slow to pick up jobs?
very slow, it should pickup faster
This one request count scaling type should pickup jobs like in 4 secs or so right?
but it took this "once" 111 secs ( from the delay time that i saw ) before it got assigned
oh okay yeah it sometimes work it sometimes happens
What is the availability of the GPU type you picked in US-RO-1?
Looking there now seems like your only good choices in US-RO-1 currently is 24GB GPU PRO and 48GB GPU PRO. The rest are unavailable or low availability. If you want to use another GPU I suggest you pick another region.

my workers are there
i mean there are like 3+ workers idle
which GPU do you use?
24 pro, 48 pro, 80gb
its available
my workers were idle
That should be fine, except for low availability for 80gb. It all depends on what is currently available in that region when you get a request. If there is not a GPU for you then it will just stay in QUEUE until there is. Next time you see your process stuck in QUEUE check the availability of your chosen GPU.
.. yeah and thats not exactly my problem here so, for this case it hasn't been resolved yet for anyone just read
Sounds like a RP bug... looking at US-RO-1 it clearly seems to have the best availability for 24/48 pro.
Okay it works now, nothing is wrong but runpod should look into this if they haven't made any changes just now haha
I'm running into something similar. I have a request in the queue that hasn't been picked up and a set of idle workers.


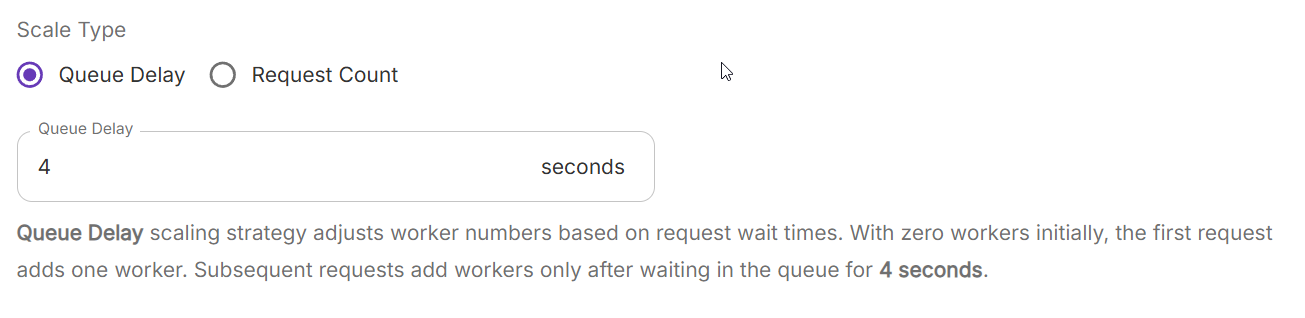
Whats your scaling type?
And you can see in the previous screenshot the request had been in queue for three minutes.
Hmm yeah
did this happens until now?
Try to open support request on the website guys
I hadn't noticed anything like this until now, but I can't be certain it wasn't an issue before.
Do you still have this problem?
Yes, getting it right now.



@Tim aka NERDDISCO Let me know if you need any other information.
Yeah that scaling is weird, im using request count 1 for now ( quick fix )
For us that's unfortunately not a great option. We're processing video and our tasks run for 10-20 minutes. We don't want someone to be waiting for that long when there's an available worker.
Yeah me too but it seems like setting scale type to req count 1 workd
@teddycatsdomino could you please use our official support mail at [email protected]? Because sadly I have no idea right now on how I can help you 😦
Of course. I honestly didn't even notice until @nerdylive posted about it! I may try his suggestion of setting the scaling type to "Request Count" with a maximum of one request to see if it does better.
@teddycatsdomino and if this is not working, please feel free to reach out. Because it might affect other users as well