async functions always finish on a background thread
Hello! I'm experienced with C#, but I'm just starting to learn about async functions and multithreading. I'm having an issue where a function that contains 'await Task.Run(...)' always finishes running on a background thread and not the main thread that it was called from. Here is my code
Is there a way of ensuring that the function that was called from the main thread always finishes running on the main thread? Thanks :D
45 Replies
unless u have a customized synchronization context (like the majority of GUI frameworks), u basically have no control on which thread a task is running.
by default they run on the thread pool threads, which the main thread is not part of
how difficult is it (if even possible) to setup my own synchronisation context?
i never did it myself, so i cant really say.
u will have to have a deep understanding on how async works internally for that
the only thing i can say: because the main thread isnt part of the threads used for the async stuff, its "safe" to use blocking calls to await task completion
oh. Are there any other ways of being able to run a function on another thread and returning control to the main thread? Like are there any libraries that can take care of that? when ive done a bit of async stuff, its always been in unity which has a synchronisation context and all of that stuff as i basically copied the above code from a unity project where it worked
well, especially because opengl was mentioned, i assume u have some kind of game loop
a naive way would be to have a collection of all tasks u want to handle once they are finished,
so u would basically just do something like
somewhere in that loop
but those tasks cant touch the opengl stuff itself, they would have to only prepare and return the data which has to be processed
So instead of just running the last bit of code that needs to be on the main thread, the function could look a bit like this? And I can't call any GL functions from those tasks that are being ran on the main thread?
Just got a basic implementation working, and Engine.IsMainThread is returning true which is exactly what I wanted, thank you! Last question, I'm calling each of the actions in the update loop, so why would opengl functions not work (not rendering, but things like GL.BindBuffer, GL.CreateBuffer, etc)?
i dont know much about opengl, i cant help here sorry
I mean GL.GetError worked so I think it's fine. Thanks for your help! :D
ive played around a bit with opencl, but never in a multithreading/async manner
yeah same, only ever done stuff from the main thread.
also note that lambdas/closures and async cause quite some allocations, getting rid of these will be important and will be quite difficult
i wonder .... do u even need to execute that all on the main thread?
my thought is: basically u only need to ensure that ur chain of GL related calles arent intertwined right?
so u could also just use some async locking mechanism like a
SemaphoreSlime and its WaitAsync()
oh no, nvm, u would still need some control over the order and it would probably introduce even more async overheadyeah, I just need my data (which is a float[]) to be generated somewhere (main thread or background thread, background thread preferred) and then the gl calls to be ran on the main thread but in that order.
im playing in my mind with some kind of generic but type based resource manager
eg one for meshes, one for animations, etc.
then u can have structs as wrapper for the tasks/jobs (not the async
Task/Task<T>) based on the resource, which can avoid heap allocations.
maybe u can even use optimistic lock-free synchronization then for enqueuing these (i mean if ya load 2 resources of the same type, maybe even with some post-processing, they probably wont end up being both loaded at the same frame right?)
another idea instead of using structs and multiple job queues and resource managers is also object pooling for those "tasks"
the latter might be favorable in case of something like lazy loading.
imagine u have a big mesh (triangle count wise), the background task loads it into RAM from disk, maybe does some bounding box computation and then pushes that into the GL affecting task/job queue.
there u could first create a GL buffer big enough to hold the data but then push it in chunks over the next, lets say, 10 frames, so the fps doesnt stutter too much.in the case of your initial sample. why even use Task.Run? you could just await some task and the scheduler brings you back to your calling task for further processing..
async methods execute synchronously until they have to
await a not completed taskdepending on the work happening here, this could be ideal. if he wants to offload all work and only return some rendering relevant data a main thread invocation method should be enough.
well the initial example shows 5 seconds of work, i wouldnt want that on the main thread
thats true. i did not pay attention of the amount of time (usually its not relevant). if something takes that long in the background and i need the value i usually go for a background operating service with signalling functionality. but i am not that much into game dev, so not 100% sure what is done for 5 seconds in background work.
The 5 seconds is much longer than the actual function takes to run, the full function takes about 250-300ms to run but it's noticeable when the function is being called many times per frame. The 5 second delay was mostly to give me enough time to see if that function is blocking the main thread or not
what work is happening there in the packground?
also if it takes 250ms it cant be called multiple times a frame because a 60fps frame is about 16ms in time...
It's a function that takes an array of voxel data (a uint array) and creates a float array with all the vertex, uv, and normal data needed to render that chunk. Also, if the player isn't moving much, this function isn't ran as it only builds chunks that haven't yet been generated around the player. Also, the time to run it completely depends on chunk size, and how many voxels aren't air.
oh so its a chunk generator. well that can be a background service. that data is not needed frame by frame. its just expanding the known rendering data.
take a look at minecraft. if you move too fast, you see chunk holes until they are loaded.
so basically it will be something like this
Would it still work for procedurally generated chunks?
well, the source of the data doesnt matter, once its done generating some batches that are "complete" u simply feed that to the graphics card
It's a function that takes an array of voxel data (a uint array) and creates a float array with all the vertex, uv, and normal data needed to render that chunk.a critical bottleneck is basically the bandwidth between host system and graphics card, so u want to compress the data u send over if u can. cant u compute the vertices, their normals and texture coords on the gpu side?
cant u compute the vertices, their normals and texture coords on the gpu side?Through a compute shader? The texture coords probably can be done in the vertex/fragment shader though
well which ever shaders fits best, point is doing it on the gpu side
tho not sure how feasible it is with this similar to lazy loading mechanics
i mean if i program it to make use of the gpu's parallel processing, i could process each voxel in parallel which would generate the chunk in a fraction of the time so it doesn't really matter if the sending and getting data from the gpu is a bit slow as the chunk building is really fast.
yeah but that will also take a time slice away from actual rendering, so finding the balance there is the bigger hurdle i guess
unity has a function for directly drawing data from a gpu buffer so if opengl has something like that, I probably won't even need to send the data back to the cpu
uhhh, yeah thats how u generally do it, allocate a vertex buffer, fill it, allocate an index buffer, and then draw using the latter buffer
there are iirc also different modes on how to interpet that index buffer, eg triangle, triangle fan and ... uh .. triangle strip or something like that?
i think i've seen those options come up for the index buffers, never used them though
its basically how the "input stream" of vertices is handled, triangle just uses the next 3 to draw the triangle, another uses the last + 2 next to draw the triangle and the other uses the last 2 + 1 next for the triangle, or something similar
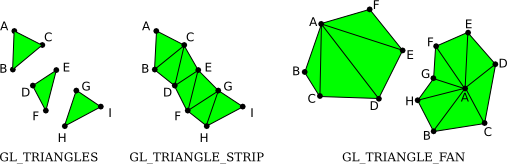{kind=link}
if I've understood them correctly, I could use GL_TRIANGLE_STRIP and that could save a few vertices? currently each voxel gets its own set of vertices which is probably inefficient
damn i cant find that one yt video ive watched recently, that was about how to optimize voxel map rendering D:
well, im not even sure if that would be apply to ur case. that was mainly about a static map consisting of voxels.
what they basically did was splitting first the triangles based on the 6 sides, combining "clumbed" voxels, and more
i think my only other option is to do what teardown does and ray trace all of the voxels, which I have actually been working on for a few week but its just taking a lot of time figuring out how to generate a BVH for the chunks. or i try to add greedy meshing which might end up being slower as actually drawing the triangles is pretty fast
the irony ... i read quite a bit in #game-dev and often watch the videos that are linked, https://www.youtube.com/watch?v=C1H4zIiCOaI&ab_channel=SebastianLague was the first time i heard about BHV, its a nice and understandable video
but i dont really think that helps with voxels
Sebastian Lague
YouTube
Coding Adventure: Optimizing a Ray Tracer (by building a BVH)
Trying to speed up the ray tracer (from a previous coding adventure) so that we can render some more intricate scenes!
Links:
● Source: https://github.com/SebLague/Ray-Tracing
● Get early access to new videos and projects by supporting on:
-- Patreon: https://www.patreon.com/SebastianLague
-- Ko-Fi: https://ko-fi.com/sebastianlague
● Previous...
(man i should start working on a raytracer again, the last i wrote was when i was 12 and didnt understand vector math and multithreading wasnt really a thing back then)
(that was around 2002)
https://www.youtube.com/watch?v=C1H4zIiCOaI&ab_channel=SebastianLagueI love this guy, I saw this video and it gave me the idea to subdivide chunks using a BVH as I had heard a bit about them from an interview with the teardown developer but I didn't really know much about it. But instead of checking a 32x32x32 chunk, it could first check 8 smaller chunks and keep narrowing it down until there are only 8 voxels to do the intersection tests on or something which will be (in theory) very fast
Sebastian Lague
YouTube
Coding Adventure: Optimizing a Ray Tracer (by building a BVH)
Trying to speed up the ray tracer (from a previous coding adventure) so that we can render some more intricate scenes!
Links:
● Source: https://github.com/SebLague/Ray-Tracing
● Get early access to new videos and projects by supporting on:
-- Patreon: https://www.patreon.com/SebastianLague
-- Ko-Fi: https://ko-fi.com/sebastianlague
● Previous...
its a prime example on how to organize ur calculations. in addition to that, from the video i cant find anymore, splitting ur cubes into sides can also help a lot.
u will never ever see more than 3 sides of a cube from one POV for example, that plus frustum culling can work wonders, i guess
Vercidium
YouTube
I Optimised My Game Engine Up To 12000 FPS
The source code and demos are available here: https://patreon.com/vercidium
The greedy meshing algorithm is available here: https://github.com/vercidium-patreon/meshing
I spent the past 6 years creating a game engine, and I've been shocked at the things that can make or break performance.
I put together 4 simple optimisations that you can use ...
The main thing I've noticed from this video that will probably help a lot is memory usage. Currently, when the player moves X distance from a chunk, it gets destroyed and the reference lost. If I optimise the memory usage to a single 32-bit integer, I could keep a reference to every chunk that has been generated (maybe destroy very old chunks or something) so the chunk doesn't need to be reconstructed when it is reloaded.
yeah memory management is the most important thing when it comes to gpu stuff
at the minute, a single vertex in a chunk uses 32 bytes of memory but my chunks are 16x16x16 (might increase to 32x32x32) which doesn't need 3 floats for position and could definetely use 6-7 bits instead. Normals could use an integer like the video showed as well. And texture coordinates can be computed in the vertex shader using a single uint for voxel id. I'll see if I can start implementing that. I did follow a video tutorial about a year ago on how to recreate minecraft in python using pygame and they condensed the vertex data into a single number and it did really help performance