Does async generator allow a worker to take off multiple jobs? Concurrency Modifier?
I was reading the runpod docs, and I saw the below. But does an async generator_handler, mean that if I sent 5 jobs for example that one worker will just keep on picking up new jobs?
I also tried to add the:
But if I queued up 10 jobs, it would first max out the workers, and just have jobs sitting in queue, rather than each worker picking up to the max number of concurrency modifiers?
https://docs.runpod.io/serverless/workers/handlers/handler-async
Asynchronous Handler | RunPod Documentation
RunPod supports the use of asynchronous handlers, enabling efficient handling of tasks that benefit from non-blocking operations. This feature is particularly useful for tasks like processing large datasets, interacting with APIs, or handling I/O-bound operations.
43 Replies
Try
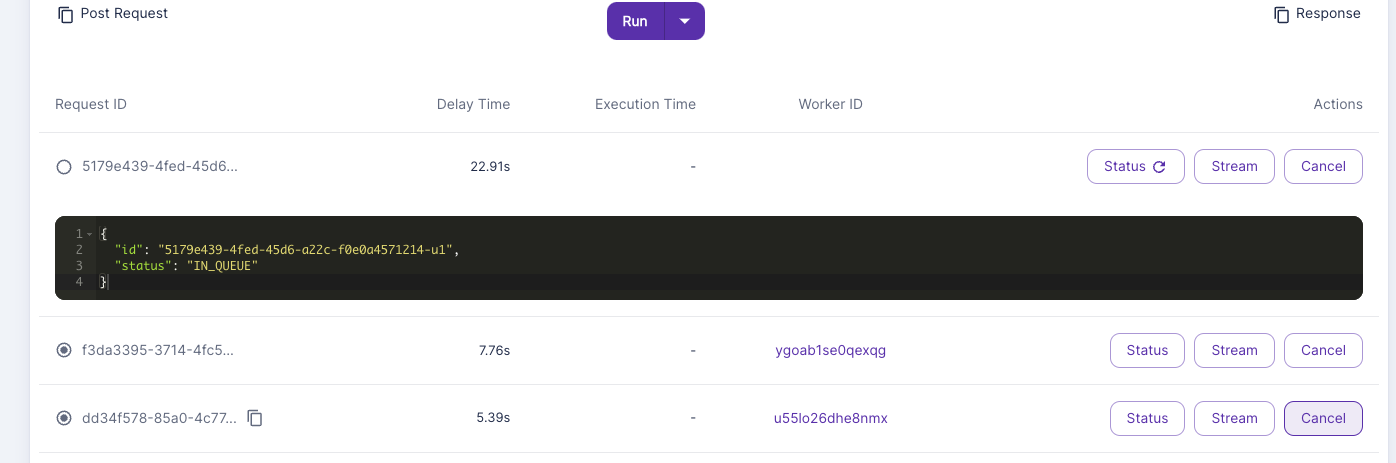
“concurrency_modifier”: lambda x: <MAX CONCURRENCY, e.g. 4>Im not sure it works? Hm. I sent like 3 requests to the handler, and the third request just sits by itself.
@Justin Merrell
Do you see anything in the logs?
Sorry meant to respond, I don't see anything in my logs? it just responds with what is expected the:
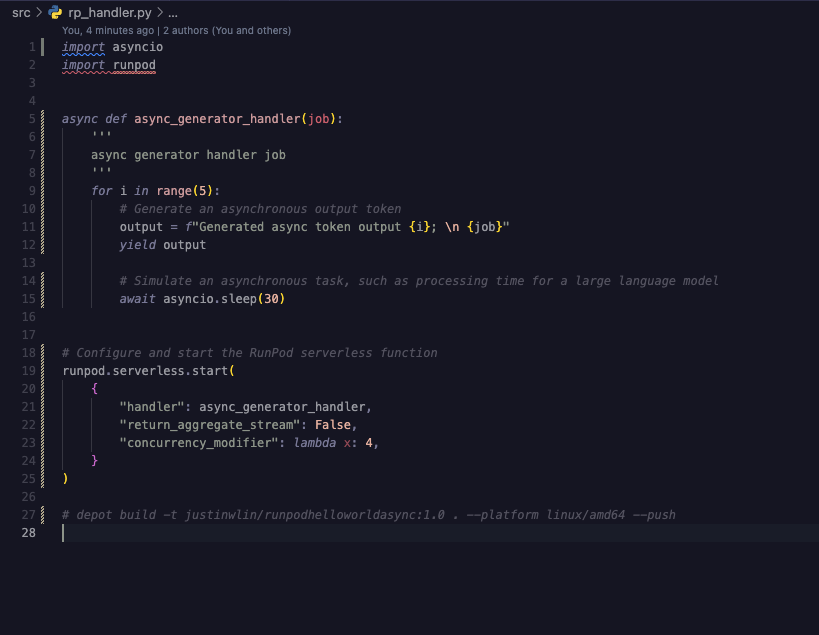
Generated async token output {i}; \n {job}
so the async generator works, it just that my expectation is if I send like 10 requests into the queue, and I have the async generator:
1. The number of max workers will first scale up (so let's say for ex. 3)
2) Meaning that now 7 jobs remain in the queue
3. That even though the worker is pending with the asyncio sleep for 30 seconds, b/c it is an async generator, it will keep pulling off the queue, so each worker will take another X-1 lambda jobs from the queue.
So that way I don't just have my jobs sitting on the queue, and each worker can handle stuff more efficiently.
@Justin Merrell Is maybe the way above not the expected behavior? Honestly, would just love to be able to have one worker take more jobs at once, just I haven't even been able to get hello world working.
The concurrency modifier as a worker level and tells the worker how many jobs the worker should try to mantain at any given time
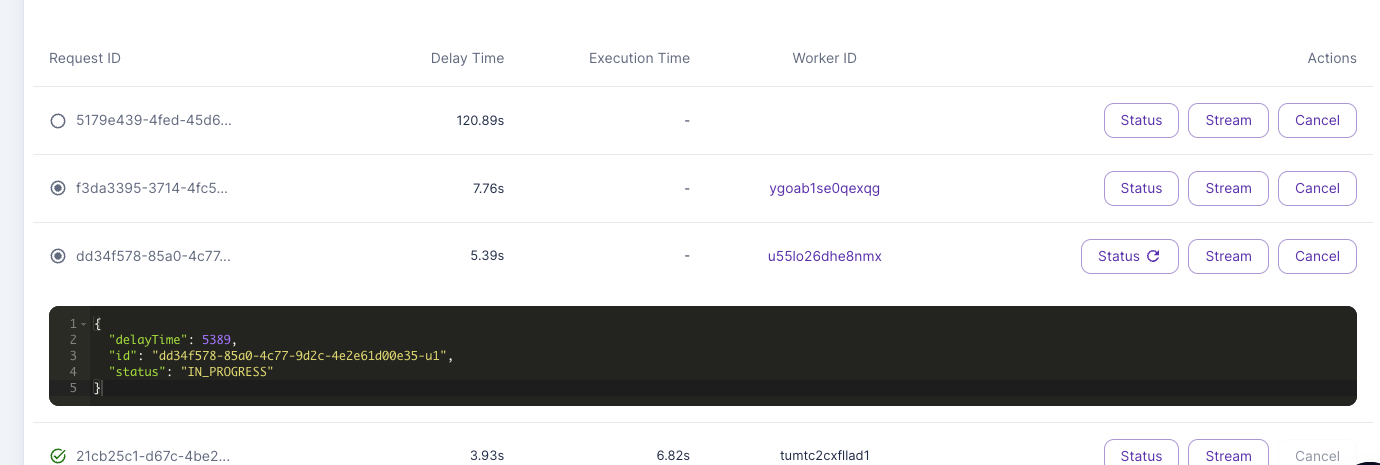
I think one of the issues is that this is maybe not properly working? B/c I can see for ex. the first two jobs have a delay time of 4 - 8 seconds, while the others have ever-increasing delay time (due to sitting in queue).
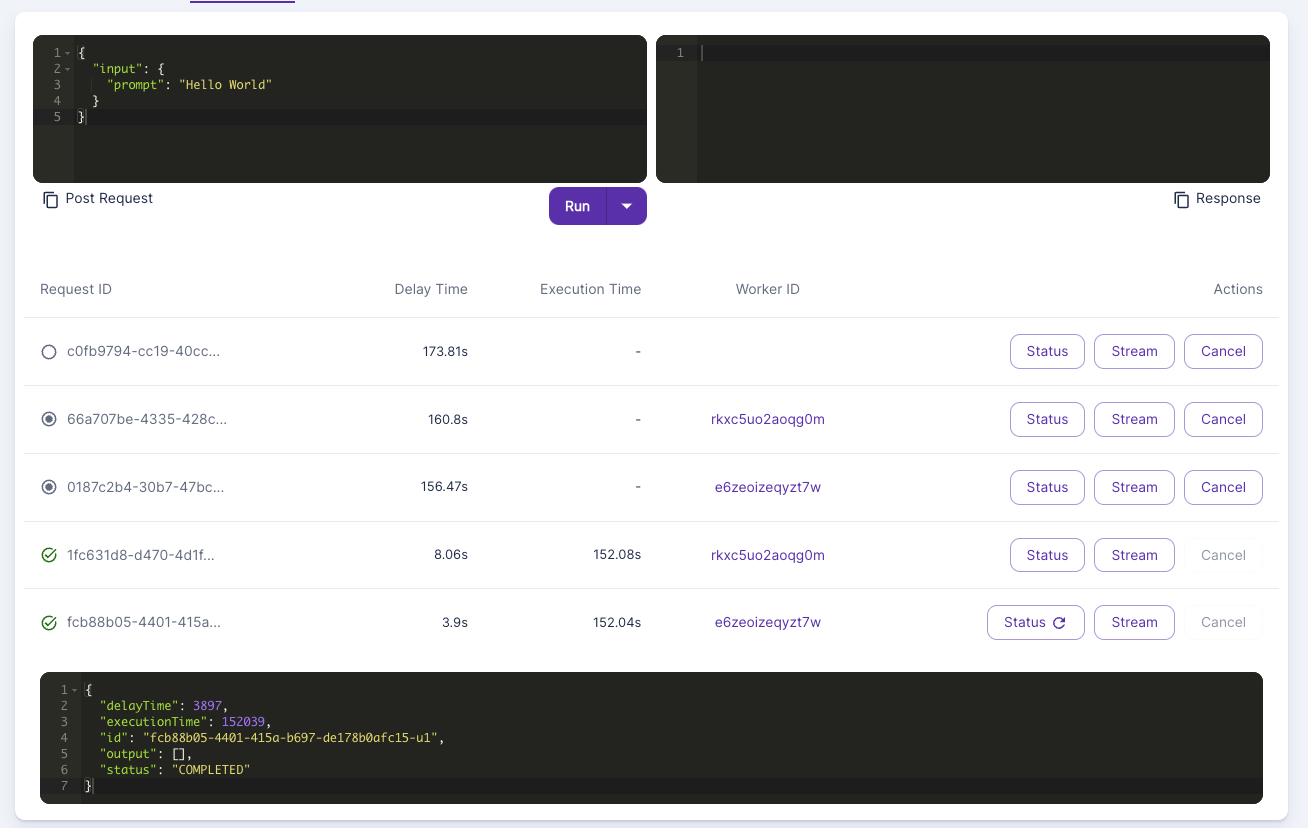
I just feel that this is unexpected behavior though otherwise that it is not picking up the jobs though still which is being defined by the
concurrency_modifier. Wouldn't expect the jobs to just sit in queue. So hopefully can give advice or check it up some point.
The below is the exact code, and I just feel it is a bit weird that I can't get something that I feel is pretty simple to work.
Try running it again with 1 active worker and 1 max worker
@Justin Merrell Tried it out, and still the same result, where essentially with one active worker, 1 max worker, only the first request is taken
@Justin Merrell Is it maybe b/c it isn't
concurrency_modifier but rather max_concurrency?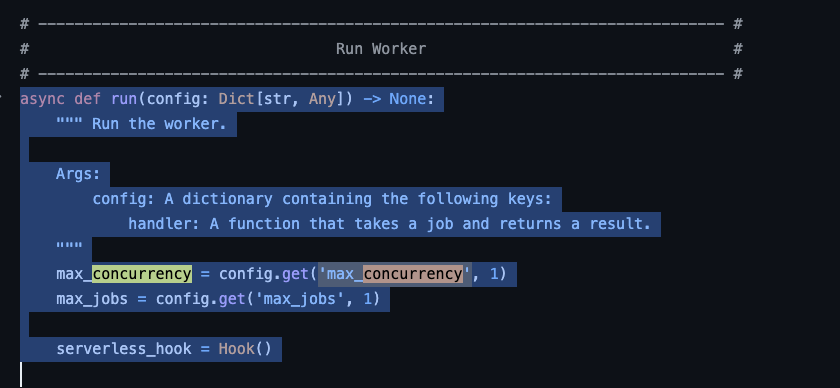
I was looking at the runpod SDK:
https://github.com/runpod/runpod-python/blob/main/runpod/serverless/core.py#L175
And maybe this is the code block where you guys are grabbing the max_concurrency from? as some sort of key?
GitHub
runpod-python/runpod/serverless/core.py at main · runpod/runpod-pyt...
🐍 | Python library for RunPod API and serverless worker SDK. - runpod/runpod-python
I see you do similar things for return_aggregate_stream, and so on.
Where is this screenshot coming from? And what does your entire handler file look like?
The screenshot is coming from:
https://github.com/runpod/runpod-python/blob/bd68176db7feb6059a3d73b41f6ec6d0d83e0f15/runpod/serverless/core.py#L218C1-L229C1
GitHub
runpod-python/runpod/serverless/core.py at bd68176db7feb6059a3d73b4...
🐍 | Python library for RunPod API and serverless worker SDK. - runpod/runpod-python
And this is the entire handler.py file
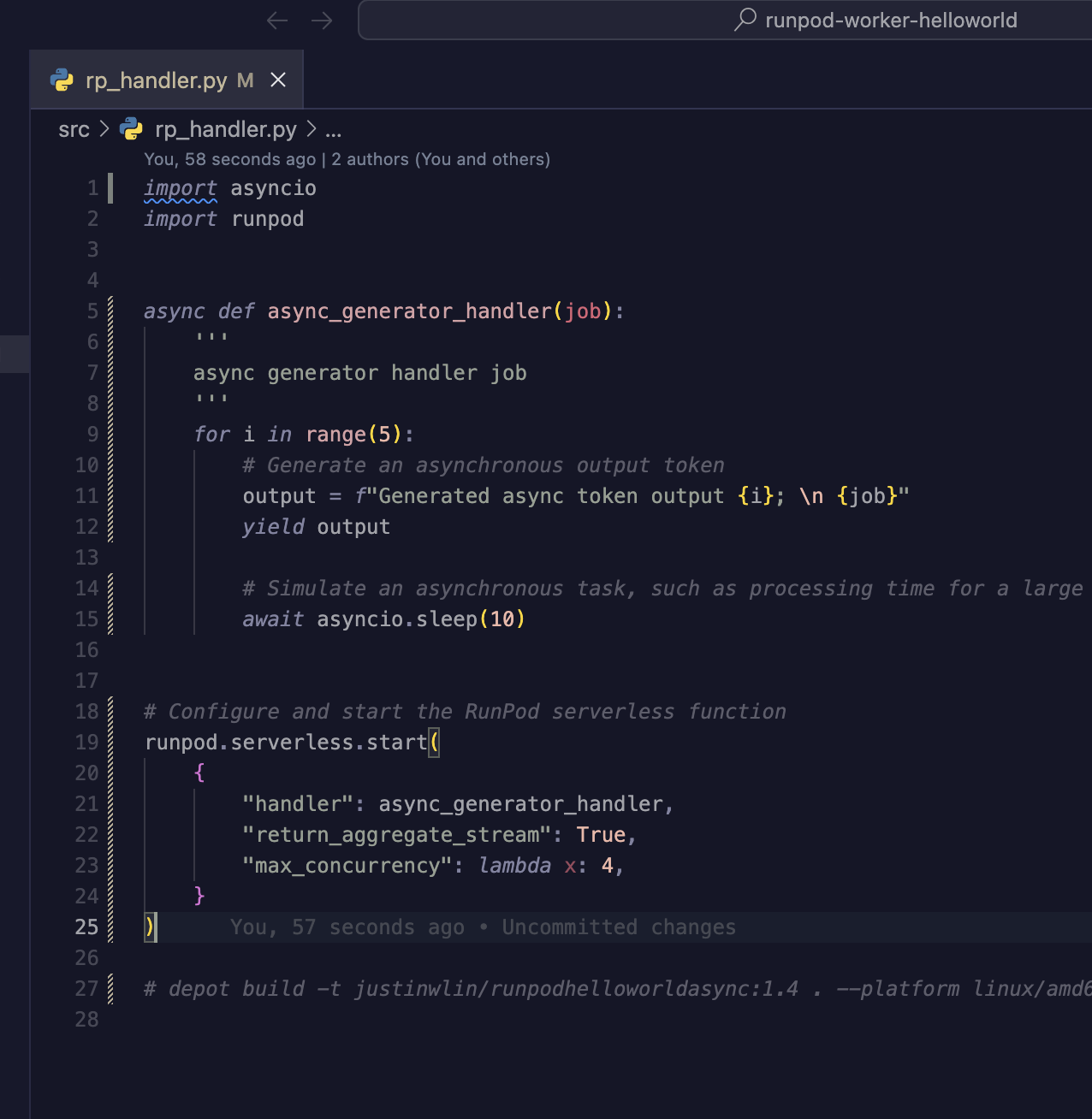
I basically just took:
https://github.com/blib-la/runpod-worker-helloworld
And then replaced the rp_handler.py with the code block I posted in the discord.
*well im trying max_concurrency now
it was :
concurrency_modifier
Oh, the code file is diffrent, re-working the runpod SDK now to make sure things are clearer.
And change "max_concurrency" to "concurrency_modifier"
Yeah, it was:
concurrency_modifier > but it wasn't working 😅.
Yeah.. anyways...
concurrency_modifier and max_concurrency both don't work it seems now 😔.
at least as far i can tellis it the for loop that is blocking? To be honest I am not a fan of python async haha https://stackoverflow.com/questions/53486744/making-async-for-loops-in-python
@PatrickR did we ever release that example to docs?
HMM. Im not too sure haha. I was just trying to follow runpod's thing on another example for generators in general:
https://docs.runpod.io/serverless/workers/handlers/handler-async
I guess, I wouldn't expect the for-loop / asyncio.sleep() to block the
concurrency_modifier? My thought is that the SDK is probably just calling the method more times and not waiting for the function call to complete, thus why the handler is given the async def
I know you said the SDK on github is out of date, but I imagine even with whatever refactoring the logic is the same:
Where it gets a list of jobs _process_job(config, job, serverless_hook), and then it creates a a task asyncio.create_task( per job in the list that _process_job
Yeah T-T. Python async really sucks.
A huge hate for it, after having to deal with asyncio myself before.
Also thought was close enough to the worker-vllm, which you guys had pointed to?
https://github.com/runpod-workers/worker-vllm/blob/main/src/handler.pyit might need that async for
Hm... I'll give that a try
Ill just get rid of the for loop
IM not sure u can do an async on the for on a range(5) iterator
at least the linter is throwing me errors
maybe adding a
await async.sleep(10) in there?I think needs to be
await asyncio.sleep(10), async.sleep(10) just gives me an error:
Tried the below still failed:
https://github.com/runpod/docs/pull/24
I have a pull request for review.
GitHub
Adds documentation on concurrent workers by rachfop · Pull Request ...
Adds documentation on concurrent workers.
@PatrickR / @Justin Merrell Does it need to be a
lambda x: 4? Or does it need to be a integer seeing the documentation that patrickR just posted?
Oh wait it prob does need to be a lambda
i see that the adjust_concurrency, is a function taking in the current_concurrency
FYI, if you could add some info on what: current_concurrency is in the docs be great. Cause the way it is right now, all I assume is its prob the number of jobs in the queue? Or it the default current_concurrency, which is 1 - which actually I think is the latter now that I read through what the code is doing.
Also the update_request_rate I don't know if this is best in the documentation, b/c this isn't something that the client is able to access as far as I know normally? Like I can't tell the rate in which jobs are entering the queue, so the example right now where that is randomized, doesn't really give me any thing corresponding if I was the client i feel, and I'd just be confused if anyone else was reading the document and be wondering, oh, how do I modify the concurrency rate based off the number of jobs in the queue? (which is why I feel the documentation a bit misleading)FYI, I tried with a modified function in the docs + also just tried to follow the docs exactly just with a
high_request_rate_threshold = 1 and I got an error both times.
ANyways Ill leave this for now 😅
I guess this just isn't working right now
@justin The function
adjust_concurrency should be written by you and for your use case. The documentation is showing what you could use and make. But there is no way the example can accurately handle each user's use case.
Also, this was added in 1.4, so make sure your Python SDK is at least on that version.
"runpod_version": "1.3.7"}Change log: https://github.com/runpod/runpod-python/blob/bd68176db7feb6059a3d73b41f6ec6d0d83e0f15/CHANGELOG.md?plain=1#L82C12-L82C17 You can check your SDK version by running:
Got it~ will give it a try! Thank you!
#THANKS to @PatrickR and @Justin Merrell The documentation examples work 🙂
Solution
😄
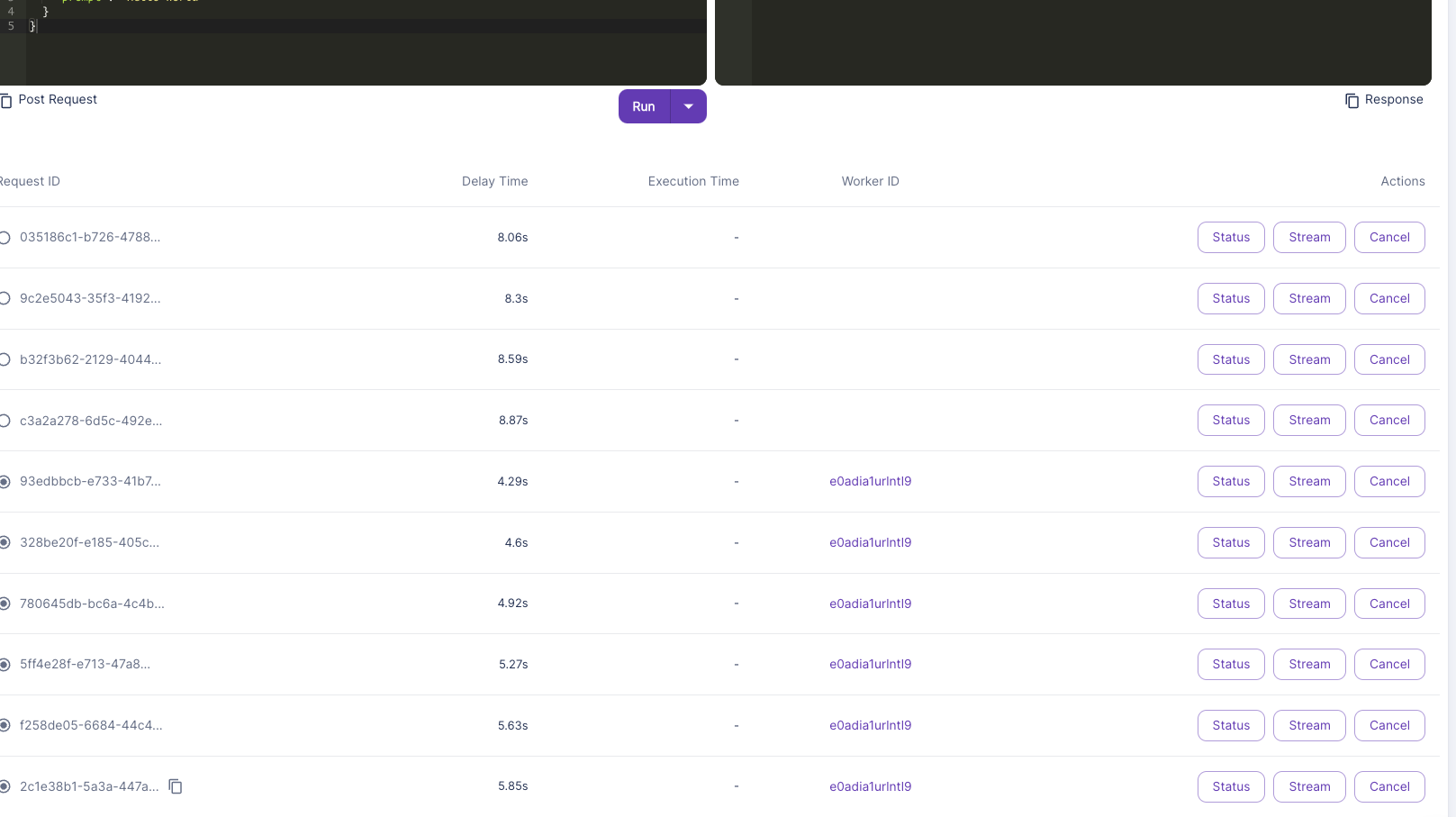
5 jobs instantly picke dup
oh lol but i still got an error.. hmm, ill keep playing with it xDDD
but interesting
Lol so close, ill keep messing with it
but at least it threw 5 errors in parallel xD
Oh
prob cause i dont have data
got it
actually
['data']
Change it to input, you were on prototype docs lol
hehe
thank u thoooo
😄
Yes. Just fixed docs to use the right key.
Yay
Im so happy
Thanks for playing along! Super great to see it helping.
Yeah, im trying to work on a busy box for runpod with like an easy base template for open ssh / jupyter notebook / all that, which I can just call and setup easily for all my future docker images
so this is super helpful~
cause i wanted to add a concurrency example
+ also my current projects
I wanted to add some concurrency stuff so im not just wasting gpu power
Thank you guys ;D