maybe this is a SSL error? local use http and http1.1 but couldflare use https and http2?
maybe this is a SSL error? local use http and http1.1 but couldflare use https and http2?
14 Replies
Its not an SSL error or an error in the workers code. Cloudflare does some basic validation on requests and if it does not pass the basic validation you get the generic 403 error. That generic 403 error means it never even attempted to forward the request to your worker or to an origin
thank, i understand, but why my request can't pass validation?
Not sure. What browser are you using, and how are you doing the request?
firefox
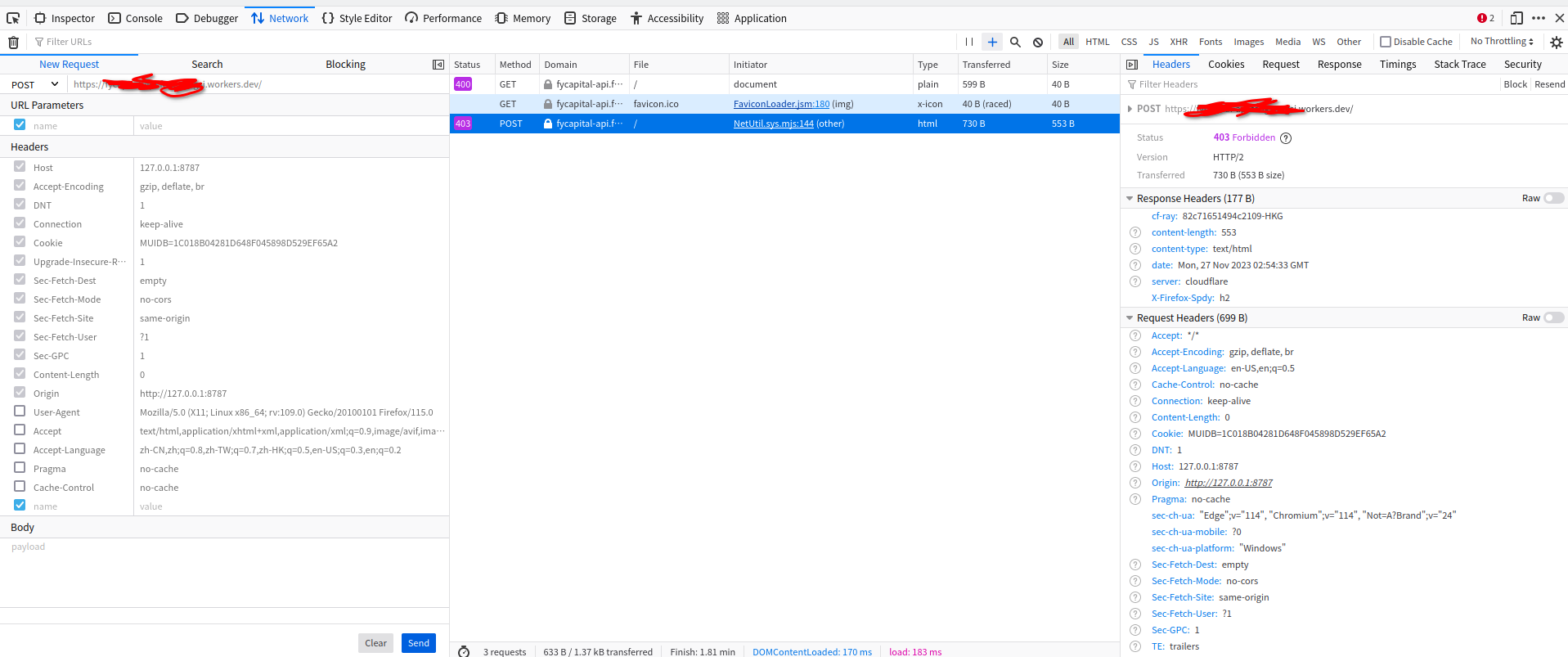
Yeah that request is getting blocked because of the host header being "127.0.0.1:8787" the host header should be whatever the domain is.
ok, it work on workers.dev, but in my domain, it return 405
it's because the pages?


just a router error, it can work now, thank you👍
Hello everyone, I am integrating the workerAI with Langchain4j to bring visibility to this great asset https://github.com/clun/langchain4j/tree/provider-workerai. Most of the features are their. I have question regarding the
text-to_Image (1) a few times i got the "upstream too busy", (2) is there any plan to add the resolution in the input request (3) what would be great value for num steps... i can try and guess but explanation would help 🖐🏻hey im getting this error with wrangler
it worked fine like 5 minutes ago
anyone knows what might be going on? There`s nothing on cloudflares status page
GitHub
Support for WorkerAI Provider by clun · Pull Request #320 · langcha...
Support for Worker AI
CloudFlare opened a Beta of a new service Called WorkerAI
https://developers.cloudflare.com/workers-ai/
They do provide a REST API for different operations.
Text Generation
T...
Unknown User•2y ago
Message Not Public
Sign In & Join Server To View
What is the CPU limit accounting when using a bound worker with the new billing system? Does the worker called with fetch get counted as part of the caller's CPU usage, or does it get its own limit?
If it were called via the network, it would get its own limit and the caller time would pause while awaiting for the result of the fetch, right? Is it similar for a bound worker call?
Are there any plans to reduce the cold start latency of workers? Its quite bad right now
Do you have any idea how much this can help/what target cold start time is? Articles like this even claim there is zero cold start, but in practice I see anywhere between 50-500ms
Spot checking response times from different locations, comparing first to subsequent requests. I had a lengthy convo with a support engineer a while ago but he wasn't able to figure out why with worker was impacted in this way, but without wasn't, so I just assume its something weird in the worker runtime