Will Mojo solve the Expression Problem?
As a software developer I want to apply Solid Design Principles to Mojo.
The open closed principle states that software entities should be open for extension but closed for modification.
In case of OOP operations are fixed but new types are introduced through vertical extension(inheritance)
In functional programming types can be fixed and new operations are introduced through horizontal extension(pattern matching)
Depending on the problem domain one over the other can be better for example if a compiler has fixed types and always new operations should be introduced on these types pattern matching might be better.
This would make Visitor pattern part of the language.
There is also I think a approach with Typeclasses in Haskell, which allows extension easily in both directions without violating ocp ,thus tries to solve the expression problem.
28 Replies
There is a plan to introduce traits/protocols in Mojo: https://github.com/modularml/mojo/blob/main/proposals/value-ownership.md#appendix-decorators-and-type-traits. This allows for the extension you mention.
As for the prevention of modification, they mentioned on the roadmap (https://docs.modular.com/mojo/roadmap) that they won't add public/private declarations for now as it is too early.
Modular Docs - Mojo🔥 roadmap & sharp edges
A summary of our Mojo plans, including upcoming features and things we need to fix.
GitHub
mojo/proposals/value-ownership.md at main · modularml/mojo
The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Protocols appear to me like a mix of interfaces and extension methods in c#. I mean in functional programming you can for example define something like shape = triangle ㅣ circle and when you implement a new function and pattern match similar like switch case the compiler forces you to implement the function for all options so you have no method not implemented error at runtime but I don’t know maybe this feature is not mainstream enough
Suppose you want to add new operation, parameter some abstract struct and you want to implement it for all possible special cases. So you would need to look up all the special cases in the code which is annoying and maybe you miss one
Vs the compiler tells you all the struct special cases to handle
Now when you add lots of operations, it gets more annoying
Afaik if you already have the new operations and now vertically extend, compiler also won’t force you to implement this operation compared to pattern matching approach, so again could lead to runtime errors
Congrats @david, you just advanced to level 2!
In case of using swift protocols
Yes, that’s what enums will let you do
In both Rust and Swift this would force you to handle all cases and lead to a compile error if you add more cases in all the places you have to fix it. This is how these languages implement the equivalent of haskell
data Shape = Triangle | Circle, and likely how Mojo will implement it too.
That is not true. When you erase type information and only have some Shape you can only call methods of the shape protocol, you can't call something Triangle has. Even if all shapes implemented a method as long as it's not in the protocol you can't use it.
There is no possible way to compile Swift code with a potentially invalid method call, unless you explicitly force downcast or use Any.Ah ok so you introduced for example a new protocol with one new operation for a string and you use this operation somewhere in your code with a more abstract type parameter and then you pass an integer into it because it is a special case of this abstract type. Then this will not compile and you have to extend also integer with your new operation
Yes if you had a protocol and added it to String like this:
Then take this function:
you would not be allowed to pass an
Int to this function because Int does not implement Drawable.
And within the function you can only use Drawable functionality because you don't know the concrete type.Nice, looking forward to type traits
To be clear about SOLID, this is the worst you can do in regards to performance. SOLID and Clean Code was developed for humans and not for hardware.
So, this is a tooling problem instead of a programming problem. Hardware evolved since the creation of SOLID and other OOP principles.
Have a look here and reconsider: https://youtu.be/tD5NrevFtbU?si=vebQwmCk_nmRB0GA
Molly Rocket
YouTube
"Clean" Code, Horrible Performance
Bonus material from the Performance-Aware Programming Series: https://www.computerenhance.com/p/clean-code-horrible-performance
Yeah, protocols are by definition very composable. You don't really need principles that try to fix OOP because it's not OOP in the first place.
They are also not harmful to performance; everywhere in code where you use a non final class, it needs a lot of additional work to handle potential subclasses, always taking the indirection cost of vtables. Meanwhile
some Shape (or Rust impl Shape) is just sugar for generics, it auto generates implementations for every type used, and allows llvm to inline and optimize each implementation individually 🙂
It's not perfect of course, but inherently a simpler and more hardware friendly idea.In my opinion SOLID are general principles. Good protocol design would also apply Interface segregation principle. Instead of having a big super class which does lot of things you have small necessary protocols which you can mix together for your specific type. Yeah in the end an engineer has to find a tradeoff between performance and maintainability and not just dumbly apply one tool everywhere.
Maintainability and performance are not diametral. They can exist simultaneously.
An engineer has to find a way to design with minimal cost in mind, too. This applies also to CPU cycles. Why design programs which waste CPU cycles because of principles which never were measured quantitively?
Here, I do not mean algorithms, but how to connect the algorithms in a structural way that does not harm execution time.
For example, you have a program written with Clean Code, small methods, and all such SOLID principles, which uses 340 cycles. And in comparison, a program structured in a way with data-oriented design, which uses only, say, 20 cycles. You are wasting the technological evolution of about 10 years only because a senior dev said, these principles are good?
Why are polymorphisms good and if/switch statements bad?
How do small methods and separations of concerns help the compiler/hardware?
On my programming career, I used Java a lot and learned Clean Code, Clean Architecture, read many books about these principles from Uncle Bob et al. Until I found functional programming, I read Grokking Simplicity and read code from game and render engines. This changed my mind a lot. I switched from Hexagonal Architecture to Vertical Sliced Architecture.
Now I try to write code with performance as highest priority in mind, focusing on data structures, knowledge- and lookup tables, padding, alignment, etc without losing readability, maintainability and such.
I will not pray for my view. This is the experience I grokked and every need his own way to enlightenment.
For example, this image is a hierarchical structure of classes, which has only concrete code in their leaf classes, everything else is only for structural overview made for human readability. This does not serve in any way the hardware architecture underneath nor the compiler.
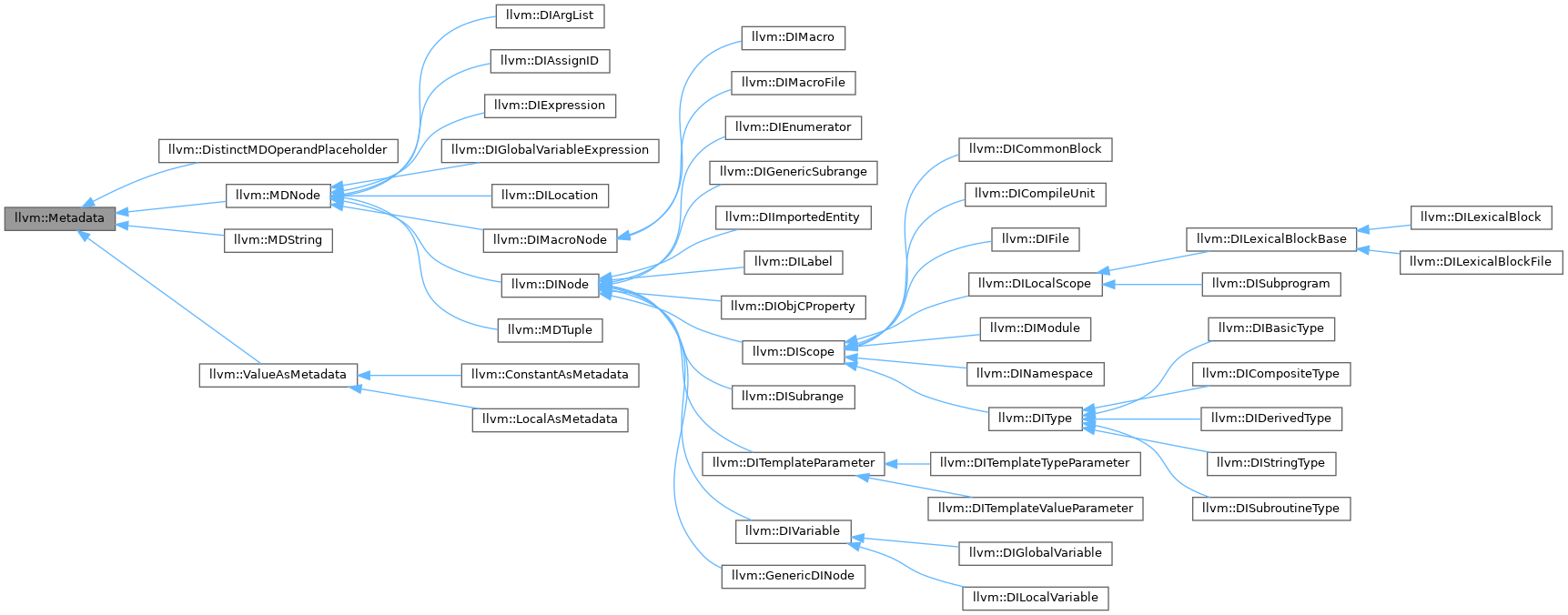
Once you use protocols enough I think you will see that they are by definition in agreement with SOLID. Those principles exist because OO is hard to get right, even ignoring performance. 🙂
People make massive classes because most OO languages don’t support multiple inheritance. You are forced to choose one base class or use interfaces which are a lot less powerful than traits, often lacking default implementations, associated types, constraints etc.
I mean with apply in agreement. By the way compiler Writer also use dependency inversion principle when they use LLVM. Since the IR is an abstraction.
So it’s not something oop specific
I've watched the video you're mentioning. I think Casey derives the wrong conclusions from his (justified) concern for performance. You don't need to avoid abstractions to get great performance in languages that have zero cost abstractions like C++, Rust and Mojo.
For the part about polymorphism, you can use static polymorphism to avoid vtable lookups and still keep the cleanness of your code (look up static vs dynamic dispatch if you don't know the difference between these two snippets):
Dynamic polymorphism (uses dynamic dispatch):
fn foo(a: MyProtocol):
Static polymorphism (uses static dispatch):
fn foo[T: MyProtocol](a: T):
So the question here is not polymorphism vs if/switch. It's static vs dynamic.
As for small functions, the reason they're recommended is for code reuse (the definition of a function is a reusable block of code). You can keep that advantage while avoiding the cost of function calls by inlining the function (@always_inline in Mojo).
I didn't understand the second point in his video (about internals) so I can't comment on how to keep performance and cleanliness there.
You can have clean code and amazing performance if you know which abstractions truly are zero cost and how to use them properly.
I'm with you, when it comes to the distinction of comptime vs runtime polymorphism.
I guess Casey is arguing against dynamic polymorphism/dispatching, but he was not explicit enough.
By using static polymorphism, you know the types a priori during writing code and be concrete over what to be needed.
By using dynamic polymorphism, you write mostly for future cases. Packing everything under a base class, like a 'Human' and an 'Ant' because they can move. This is the inheritance problem. Solved by utilizing composites (a concept also from OOP). You see, I do not doom OOP at all. It has its use cases.
Why I try to encourage people reconsidering OOP, because of overengineering it. Like a hammer for everything which looks like a nail.
In Mojo exists the 'alias' keyword as tagging and for example create a Matrix 'object' like
alias Matrix4x4 = SIMD[float32, 16] (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0) (<- pseudo code)
If someone is coming from a strongly OOP educated direction, explain why to use a 4x4 Matrix is better over of a 3x3 Matrix, even if you only need 9 elements as in a 3x3 Matrix and can put aside the other 7 elements?
Or explaining, why a 'Person' class, with member variables such as 'name', 'email', 'age', 'profession', 'wage', 'bonus' etc., is a bad choice, if you want to calculate the yearly wage + bonus for 500k Person instances?
About code reuse, it makes sense to put proven algorithms in a library for later use in other similar projects or similar apps. What is the difference between:
and
The former is the vertical layered architecture and the latter is the horizontal layered architecture.The "internals" part seems to be about encapsulation.
In object oriented programming, as it was originally intended in languages like Smalltalk, you're supposed to use messages exclusively and avoid anything that exposes internal state, that includes getters. The design was supposed to be completely detached from implementation.
Personally I dislike the concept of "zero cost abstractions", as much as the Rust and C++ communities love to say it. You always pay for them in compile times, and even at runtime if you're unlucky and something isn't optimized away by the compiler.
While Casey's opinion on abstraction usually seems to go a bit too far, I do agree that conforming to arbitrary programming ideologies instead of just writing code is not very productive.
Although lately it seems like rejecting abstraction is becoming a programming ideology in itself 🤣
If this will happen, we would go back to asm and write hand-crafted loop unrolls. 😂
Indeed.
You could also use macros for zero cost abstractions. For example you have a more readable mathematical expression and then use macros to code generate a more evaluation efficient math expression, also compile time or static.
There's no such thing as a more evaluation efficient expression in compiled languages, modern compilers optimize things to basically unrecognizeable state and will almost always make better decisions. If by some chance a certain way of writing an expression generates more efficient code it's luck and should not be relied upon.
https://youtu.be/w0sz5WbS5AM?si=ommtb1DKbakC08yB
This is an interesting talk about such compiler optimisations
cpponsea
YouTube
KEYNOTE: What Everyone Should Know About How Amazing Compilers Are ...
https://cpponsea.uk
We use them every day, but how often do we stop to think about the kinds of amazing things our compilers do for us? Modern compilers are a feat of engineering and in this talk Matt will demonstrate just a few of the very cunning things they do for you.
Matt will concentrate on the output of the compiler: the tricks they use...
The Mojo team has said that the Mojo compiler isn't "magic". I don't know if it will perform all these optimizations.
Most of that is actually done by the backend, like llvm, not programming languages
Oh ok
Not doing these things is a death sentence for a language if you want abstractions to have no (runtime) cost.
Here's an example of a very naive rectangle drawing method from a software renderer I made:
The "zero cost" abstraction here is the
Range syntax, which constructs a range and then calls next() on the iterator in a loop. In release mode it's optimized away and no slower than a C style loop, but in debug mode this is too complex to inline. The cost of actually using the iterator in the most critical part of the program here takes this from lightning fast to literally a slideshow just clearing a 320x200 screen to black, not even drawing anything (on a very fast cpu).
This is a great example of one the less obvious costs of "zero cost" abstractions. Suddenly I can't use debug mode for this program, the gap between optimization levels is significantly worse the more you rely on the compiler to optimize away abstractions.
Release mode prevents incremental compilation on top of further increasing compile times, so you don't want to be using it all the time.
"zero cost" is sadly not even true for the most basic of things. You only move the cost elsewhere.I believe they originally said this with respect to the more dynamic, python subset of the language. Specifically that the python subset would, at least initially, be focused on compatibility, providing a compiled of python implementations which interop with the systems programming superset. The performance benefits there would come from removing the python interpreter overhead. I believe the dynamism proposal can give more insight into how they're thinking about this.
https://github.com/modularml/mojo/blob/main/proposals/mojo-and-dynamism.md
GitHub
mojo/proposals/mojo-and-dynamism.md at main · modularml/mojo
The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.