Translating bytecode into JupyterLabs compatible script.
I've found that the gremlin syntax in jupyter is different from every other language, including python. For now i've resorted to copying the java PythonTranslator into a new class and modifying the code to suit the differences. Does a better way exist?
10 Replies
Are you using an existing library within Jupyter? Are you familiar with the Graph Notebook project, which has a custom
%%gremlin magic? https://github.com/aws/graph-notebookGitHub
GitHub - aws/graph-notebook: Library extending Jupyter notebooks to...
Library extending Jupyter notebooks to integrate with Apache TinkerPop, openCypher, and RDF SPARQL. - GitHub - aws/graph-notebook: Library extending Jupyter notebooks to integrate with Apache Tinke...
^^ Not just meant to work with Neptune, but with other TInkerPop-enabled databases.
Yep i'm using the graph-notebook library as per neptune documentation, forgot to mention it. I'm trying to use a translator to get the query script out of an aws lambda (running with the java gremlin driver) in order to profile and sometimes debug them inside notebooks.
There's certain differences like maps being translated within {} instead of the needed [], the steps not having underscores or boolean values not being capitalised.
The groovy translator isn't a good fit either because of type casting and a lot of parentheses that it can't understand.
Fortunately the translator code is pretty easy to understand - thanks spmallette and Marko - so I made myself a custom one for the time being, although I feel like I'm missing something if i'm the first one to run into this problem.
I know there's a profile step but I don't think it accounts for neptune's optimisations, at least i haven't noticed it in the profiling section of neptune's docs, so i'm profiling queries in jupyter.
could you provide an example of what is not translating properly? the entire Gremlin test suite relies on the translator infrastructure to work so i'm surprised to hear that there could be massive gaps there.
Sure, i'll provide an example tomorrow
Translator outputs:
Driver code:
Not sure how good that custom translator is for all of the data types cause I haven't really used most of them but the query works in jupyter. I used logging to prevent any string escaping happening
@neptune any ideas on where things are amiss here?
Will take a look @spmallette - is the issue here that the Gremlin generated from the code cannot be used in a notebook with
%%gremlin ? The Notebooks don't need the Python form if so. They just send the queries as text (over a WebSocket) - so the Groovy form should work so long as it is compatible with the Antlr grammar that TinkerPop uses.
So the flow should just be Java --> Groovy Form (aka basic Gremlin form) --> %%gremlinThanks for the response, the groovy translator I was using for this example is the default one you create with GroovyTranslator.of("g"). I mistakenly based my translator on the python one so I'm not as sure what differences there are between the script it returns and the one that works in jupyter, but I can at least say that it returns an error:
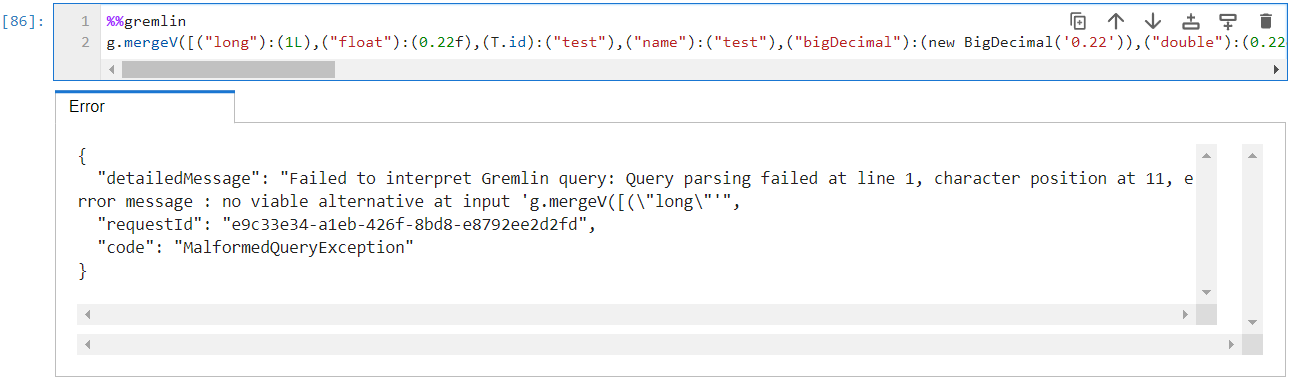
Seems like most of the map parenthesis need to be stripped and non-primitive typecasting like the bigDecimal one is somewhat wrong using new, although I have no clue about the type constraints on neptune or tinkerpop so I can't say that it is a problem
"int":(int) 1 is also not usable it seems, along with VertexProperty.Cardinality.single
oh, i think i see it now. Neptune doesn't use Groovy to parse Gremlin. It uses the Gremlin ANTLR grammar. The ANTLR grammar is fairly close to Groovy syntax but not quite in all places (those places are typically in language areas core groovy syntax doesn't support). I think i'd classify this as a bug in the translator because the translator is just playing it safe with the keys. It's not really generating idiomatic Groovy, which in turn is not expected by the ANTLR grammar. Created this issue: https://issues.apache.org/jira/browse/TINKERPOP-2922 - it will be fixed for 3.6.3 which is hopefully releasing soon. Thanks for reporting this as it's definitely an important issue to fix given the prevalence of
mergeV/E() usage that's take Map instances. Appreciate the patience in getting to an understanding on what was going on.