Hitting memory limits again?
Hey, so a couple months ago when we started using workers for delivering game content (using R2 as a cache layer), we ran into an issue where files that were larger than 128MB caused the request to fail at 127.99MB. We solved this by better utilising
response.body.tee(), but the issue is back again as of this morning.
Nothing has changed with our workers code, we essentially left it as-is once we got it working how we wanted it to, including serving files in the 300MB-800MB range.
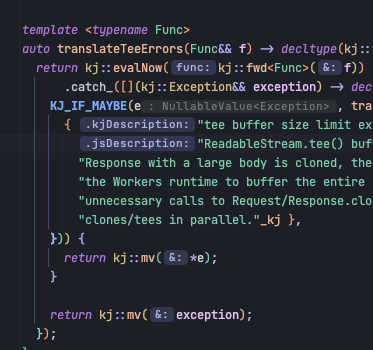
This is the code that we currently use for delivering the response, the same code that this is supposedly failing with:
It's worth noting that I cannot tail the worker as it's getting too much traffic (250+ invokes per second) so getting logs are out of the question.
If there's anything here that can be improved, I'd much appreciate it if you could point it out. I'm not very familiar with streams so it's possible that I've made a mistake here.
Thanks 🙂14 Replies
It's worth noting that I cannot tail the worker as it's getting too much traffic (250+ invokes per second) so getting logs are out of the question.You can filter
tail to only be from your IP, or another one.I didn't know about that, but that's an incredibly useful tip
I'm not very familiar with streams so it's possible that I've made a mistake here.You could run into issues if one of the streams is being read slowly - i.e a slow internet connection from the upstream
I'll look into that now
we have to use a little hack where we reverse proxy the source of the files using nginx so that workers can pull from it (port restrictions)
Yeah
The exact error I have open right now, haha
I guess this is a new change with workers? this never used to happen until today-ish
No idea on the exact date but it's been there since the release of the OSS runtime, so earlier than September
that's before the time where we started to use workers for this
do you think the
await could be the issue in the above snippet on line 12?
thinking of this:
To fix this issue, remove unnecessary calls to Request/Response.clone() and ReadableStream.tee(), and always read clones/tees in parallel.there's no clone calls, and only one call to
tee()I'd say so, yes.
You can do your
put in a waitUntil but that means the upstream must download the file within 30 seconds - currently.Stack Overflow
In a Cloudflare worker why the faster stream waits the slower one w...
I want to fetch an asset into R2 and at the same time return the response to the client.
So simultaneously streaming into R2 and to the client too.
Related code fragment:
const originResponse = await
that seemed to have worked
thanks @kiannh ❤️
No problem