333 Replies
big thonk

i have no idea what that function is
glVertexElementArrayBuffer
what
also do you know why i have to create a new VAO for each set of buffers
beyley

what the fuck
how else do i detect ogl version
you create a gl context and get the version :)
this information is true
but
the driver lies
that was the issue

I swear
bruhhhhhhhhhhhhh
at least do it in another process
just put it in another process
easy
done
how does it lie exactly?
ive dealt with old intel drivers that claim 3.2 support but dont actually let you create a context higher than 2.1
its a PITA
so i just try EVERY opengl version
how does that even work
the opengl string says its 3.2
but fails to create context on higher than 2.1
old vista/7 era drivers are cursed man
i assume you were requesting a legacy context
i was requesting a core 3.2 context
renderdoc is very confused

as am i
also the colour of that pentagon is still wrong

then how do you get this string before creating the context...
I think something is giga wrong with the color format
if i create a 2.1 context it says 3.2 in the string
wat
don't depend on the string then?
i dont have access to any 3.x functions like VAOs
the red blur
that is what I get from the texture
is there specific function calls to get the ogl version?
What you could do is pull a Blizzard with older systems, where they run a compatibility tester that checks everything and auto selects best options based on what the system can handle
i was just looking at the version string
yes, in integers
o
well i just did what veldrid did
and assumed it was fine
which is try every ogl version
mellinoe certified 💥
I'm suspecting you're doing something wrong with textures

that is the input
how
its fine on both NVidia and Intel
textures are RGBA32
glGetIntegerv(GetPName.MajorVersion, &majorVersion);
glGetIntegerv(GetPName.MinorVersion, &minorVersion);
dont i need a context before i can do that?
you do
how would i know what version to use for the context before i run that
wont that return the version of the current context
you request a context with the biggest version
5.0
it does
so i just tell it to do 4.6 then check it?
wont the driver just fail to create the context if its too high
thats why i do the brute force method
i could just shove it over to another process, how would i do that while keeping it in the same main codebase?
pointing out that this
fixed(void* ptr = &accessor.GetRowSpan(i).GetPinnableReference()) is cursed and a GC hole, and you should do fixed(void* ptr = accessor.GetRowSpan(i)) instead, which is also easier to readoh
GetPinnableReference is just there for the compiler to use when lowering
fixedah
it should be fine though, it shouldnt cause heavy texture corruption
(ill fix the code rq dw)
pushed the fix for that specific line
i still dont know why the textures are that fucked for you though
they shouldnt be
unless your card doesnt support RGBA32 textures
which would be silly
actually pinning the span has improved it somewhat

how
okay
uhh
im updating textures row by row
it should be impossible for the data to be in the texture like that
i can see a semblance of the texture
can you send the original texture?
For example, if the format is GL_RGB, and the type is GL_UNSIGNED_BYTE, and the width is 9, then each row is 27 bytes long. If the alignment is 8, this means that the second row begins 32 bytes after the first. If the alignment is 1, then the second row begins 27 bytes after the first row.probably this?
what
how can i tell it to not be aligned at all and just let me upload the darn data
something changed

how tf
also still very weird that the vertex colours are different for you
which driver is at fault here
mine or yours
it should be a really colourful pentagon
not 2 colours blended
I think in general AMD drivers are just more strict
not really worse
just more strict
but im following spec i think
so my driver is at "fault"
i dont see how a basic set of tris with vertex colours wouldnt be following spec
but nvidia is likely doing things not explicitly said in the spec
I mean you also have the same texture bound 31 times
so I'm assuming the code is still a bit buggy
different textures same data
it's just for testing
i'm not sure if the glsl version you're using is compatible with the newest opengl
oh
that might actually be it
so the AMD drivers acts very mature and corrects you :)
an error message would be appreciated
is this art?

maybe
save it in high quality
i want that as a background
god why is opengl such a moron
you need to set context version before you create a window
why does a window even need to know an opengl version 
nightmare
{kind=link}
Reminds me of my childhood days turning the tv onto the SNES channel before turning on the console
Nostalgic
thx
the art of graphics programming

is there an easy way to make the engine not use Tex0 anymore?
like for rendering object?
?
maybe the AMD driver isn't quite done yet
make it always use tex1+ only?
and it's still loading images by writing them to tex0
yes
uhh
just tell it to start binding from tex1
in Draw
but then objects that were supposed to use tex0 fail?
o righ8
in get texture id make it return +1
then start binding from tex1
both of those or only one?
both
so I make it return + 1
and in draw I start the loop +1
ugh i cant upload screenshots again for no reason
omg discord PLEASE
change the function to this
{kind=link}
I don't think that worked
then do that
that should be the exact same but starting from texunit 1
ok 1 sec
Toss them on imgur temporarily and just link here I guess
Lmao

i just uploaded the code itself in a codeblock
lmaoo
same
weird that the top left vert is the wrong tex
im going to try upping the GLSL version
I mean that looks like the texture is loaded correctly
yup
it's just renderdoc pissing itself about the format
lmao
in the OpenGL project go to the shaders folder, then change the GLSL version to 410 or 450 or smthn
for both vertex and fragment
its possible 140 is not liked by your driver
if so ill just write some code to convert between the shader versions at runtime
im already gonna have to do it for GL2.0 anyway
{kind=link}
it looks different every time
I have no idea what's going on
looks like renderdoc is pulling uninitialized ram
for no reason
no I don't think so
I think
oh
The fuck is going on there
tex coords
Because OpenGL loading is window dependent IIRC
But the upper left triangle
idk
probably a different texture
It is two colors blended, then the test are your texgyre
How the fuck is it using two different textures in a draw call without him fucking something up royally
Or you
what
you can easily use many textures in a single draw call
I just removed like
everything
shader is now only

Yes, but not just arbitrary pick which one per triangle without modification
and

texture is per tri yes
and it still doesn't work
You use a texture per tri?
i am in pain
this makes no sense
yes i have realized, but i shall not accept it
AHA!

It kinda works now
It's dumb
thats kinda better
that's expected result
i can see the outlines of the cirnodons
what is tex_8
the 9th texture slot
i don't think gpus like this nonuniform access...
shhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
its opengl it can do whatever it wants
it would explain why AMD dies but nvidia doesn't
You should try it on Mesa
ok
i think it's architecture dependent...
Mesa is super strict
building the latest build then ill slap on mesa software rendering with
__GLX_VENDOR_LIBRARY_NAME=mesa LIBGL_ALWAYS_SOFTWARE=1 MESA_GLSL_VERSION_OVERRIDE=450 MESA_GL_VERSION_OVERRIDE=4.5 MESA_DEBUG=1 environment varsoh right i forgot you can do software rendering
more progress

There is a reason a lot of MC shaders don't run on Mesa
mesa isnt drawing imgui now for some reason what
so texture loading just doesn't work
but everything else kinda does
oh there it goes it just took a sec
mesa is kinda happy

not perfect tho
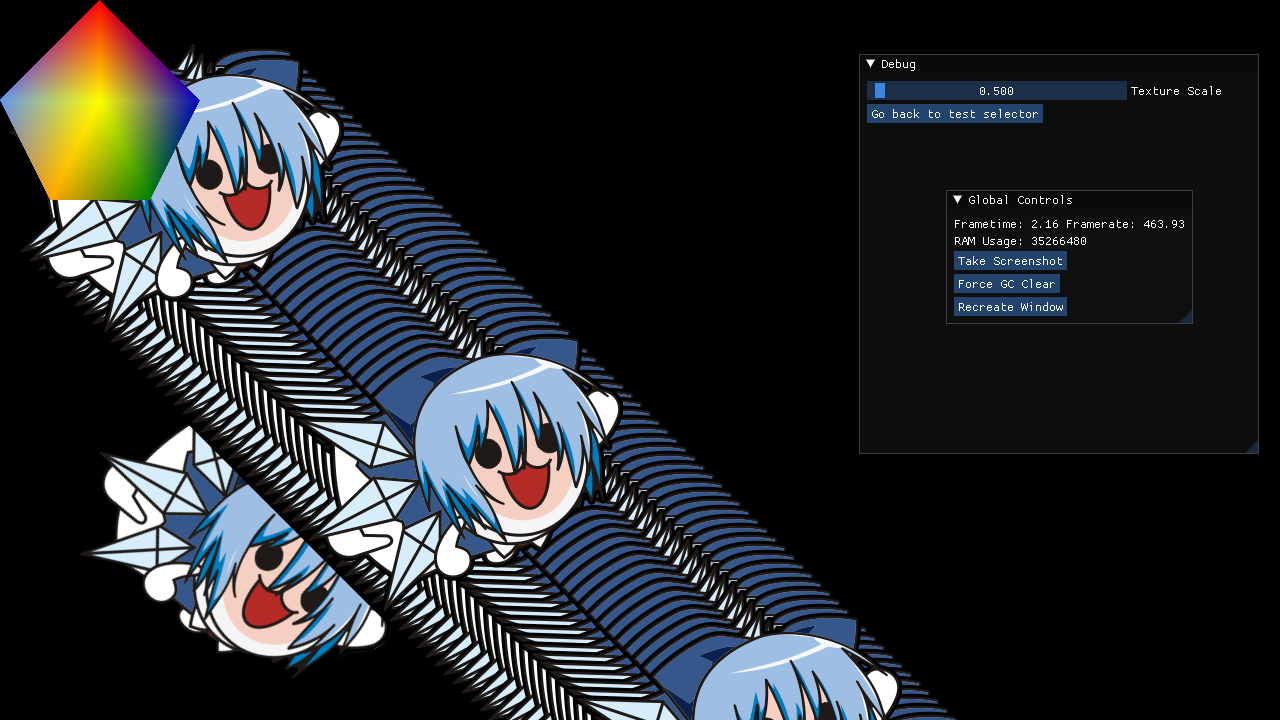
but also only because https://i.kaij.tech/file/2022/08/rider64_nM8g32VsQ7.png
{kind=link}
I just set the texture id
with a small change: mesa works perfectly

(i reverted the 'start from tex unit 1' patch)
dont be fooled its not running at 300fps
its running at 5spf
well 'perfectly' meaning its not completely broken, just like nvidia and intel, the draw order is still a little fucked but thats probably some off by 1 logic somewhere
I gotta go for now
o
i can't be bothered with more opengl today
it hurts
this is my current draw function
although fun fact: my voxel engine has the same performance in all backends
i optimized the opengl backend to hell and back
niice
oh at least the program isn't re-bound every draw
ye
also the unbinding of buffers does make it a good bit slower probably
oh right i probably dont need to do that
just wanted to keep the state clean
maybe make Unbind calls debug-only?
a valid program should not need to ever unbind :P
that seems reasonable
tf

not worrying at all
oop i found the issue
im reserving the data before i know whether i need to create a new buffer for a new texture
i think i can solve that by making you pass in a texture for 'reserve' too
then it returns your tex id with it
yeah thatll work
:p
there we go its fixed

now we can see what carnage the 2k quad test does
solid 23fps
hmmm
renderdoc claims 23fps too
all 2k quads is done in 3 draw calls
3 draw calls including the pentagon
2 excluding the pentagon
not having a debugger attached and disabling unbind still only nets me exactly 23fps
now i just gotta figure out how to not have to create new vertex array objects for each buffer
yeah only the last buffer draws
if i just have a single VAO
okay yeah the buffer for elements 0 1 and 2 is getting reset by the last buffer to be created
cus the vertexattribcalls
hmmmm
i have no idea how to solve that lol
ok so a VAO holds refs to vertex and index buffers
and you need to enable each array element or the gpu wont read the value
how quirky
whats happening is that the vao's buffer is being changed to the last one
so im basically just drawing the last buffer over and over and over
can i just not use a vao :^)
i can send a renderdoc capture if you want
veldrid doesnt :p
oh neat
how would i go about not using one
cus i just wanna bind the vertex buffer and have it use it
i tried just commenting out all the vao code and what
invalidoperation on unbind

oh god
you need vaos in the core profile
veldrid uses a single global vao
yikes
opengl is so terrible
damnit
to be able to do this id need to rerun my vertex attrib ptr calls every draw for every buffer
id bind the global vao, bind the vtx buffer, run the vertexarribptr, then draw
i dont know if thats better than just having separate vaos
well, your batcher is currently disposing the vao every frame so :p
no sorry
disposing the vao every begin not every frame
every rebuild
ye
its still bad
i know ill fix it eventually
i still dont understand the horrible fps though
it doesnt make sense to me either
i profiled it and most 95% of the time was spent in silk windowing
i just pushed the single texture stuff rn
pull that
which i expect was the automatic swapbuffers
its 1fps faster than multitexture draw
1
22 -> 23
i will test it in 30min (entering shower rn)
cool sounds good i got chemistry class now anyway :^)

is what my profile shows
(make sure to limit the view to the main thread)
dear lord how long are you in school
for another 2.5 hours
beuh
i get to school at 8:30, leave at 15:40
i just had a shower thought
it's probably silk autoswapping way more than you necessary
and your fps counter doesnt count the swaps
i mean renderdoc also claims the same fps counter
23
hmm right
but theres like no way that your app takes that much gpu and cpu
yeah it just doesnt make any god damn sense
im so confused
what happens if you turn on vsync
its actually only using 12% of my CPU
lemme try vsync
it maxed a core for me
and 100% gpu as well
and i have worse hardware so
vsync causes no change
:|
like it caps the fps
but it doesnt help the problem
2k quads with basic instancing and multitexture is 83fps
but i really wanna support arbitrary meshes
dont worry we'll figure it out
coolcool

this should be way faster
is there any opengl state thing that i should set? cus i do set cull face mode but i dont know what else i should set
i took a look aswell and didn't find anything unusual, and im pretty sure the low fps is just due to the fact you are drawing 2000 large quads stacked on top of each other with overdraw, massive fragment fill rate abuse
yup, i feel silly for not mentioning it earlier
creating sprites at scale 0.01f and now i have 700fps
it was all from the bloody overdraw
a million quads at 170fps with batch size 1024, good shit
1M quads at 180fps with batch size 64K
it can rebuild 100K quads every frame, very cpu bound
oh
@baebey ok you have to start reusing buffers

opengl shits itself
lmao yea i'll do that once i'm in a class i can use my laptop in
//TODO: make VAOs optional (for pre GL3.0)and this todo is a step backwards
i'm in math class rn lol
?
using VAO everywhere should in theory be simpler
instead of creating two different paths
no vaos in 2.0
so i don't got a choice
oh ok
pain
it should hopefully be easy
i think in
Begin() i'll grab all the buffers that were used and drop them into a list, then grab them out of the list when needed, and allocate more once the list is empty
should be ezsounds good to me
actually the list should be static so multiple renderers can use the list
:|
why :/
i'll do a count of how many renderers there are and make sure that it gets disposed when all are gone
i just don't like any static data, you can do whatever
ah
ittl mean possibly less buffers used which is a plus
No static data = easy recreation and unit testing 👀
with how i'm going to track it easy recreation will still be just as easy, cus you need to dispose all renderers anyway to recreate
i scaled the cirnodons down to 0.05f scale
4000 fps
2k quads
1.3k fps if i regenerate the thing every frame, (with buffer saving)
so i reuse buffers now
if you want more rebuild speed you can easily just reserve more at once, it's a great system 👌
the only problematic scenario is requesting more than the max batch size
i just did this and am going to let later me deal with it https://i.beyleyisnot.moe/HwBnhFc.png
{kind=link}
better than nothing
the max buffer size is enough to fit 1024 quads
so thats 4096(?) verts
and 1024*6 indices
which should be more than enough for most cases
try not making it too big in your current setup because you create a new buffer per texture right?
unfortanately so yea
i should drop it to 256 quads in that case yea
thats still a LOT of verts and indices
and not too big to cause problems
okay now that OpenGL p much 'just works'
time to do veldrid
look at me using fancy bitmasking https://i.beyleyisnot.moe/3W2Z5Xw.png
{kind=link}
this is to ensure usage is only indexbuffer or vertexbuffer
veldrid checks that already :-p
for just normal
CreateBuffer?{kind=link}
i dont see why you couldnt support more usage types
is it time to make a veldrid-cursed thread 
yes
@baebey update on AMD problems:
whwhat
aren't location qualifiers for outputs only for vulkan?
are they?
looks like it
removed the extra qualifiers
try pulling now
what's the variable to for GL again:?
what
the env variable
to say it should use GL
o
VIXIE_BACKEND_FORCE=OpenGLIT WORKS
{kind=link}
wooooooooo
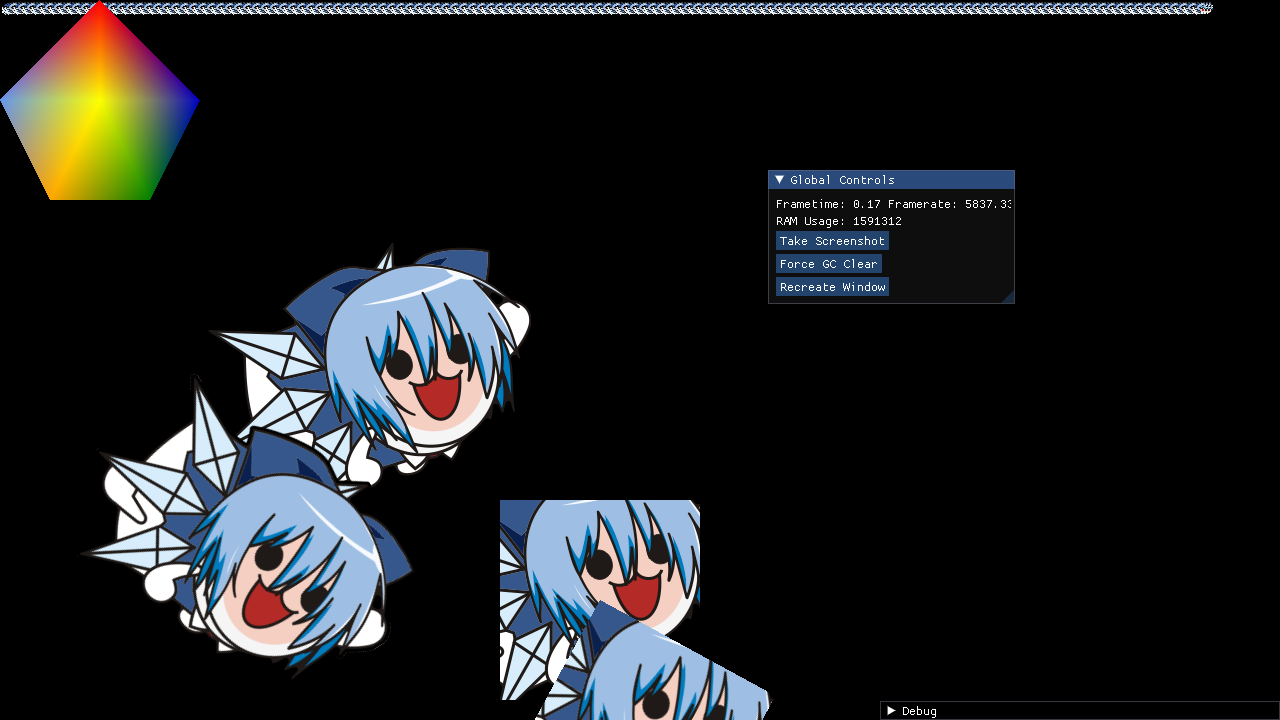
wait can you move imgui out of the way so i can see the pentagon
{kind=link}
yup thats correct
eyyyy
I mean
finally
I'm sad its' not SRGB
so the pentagon is kinda sad
but still
🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉 🎉
replace the test scene file with that
{kind=link}
whats the average perf?
5.8-6.5k frames
eyyy
lets go
also now
that kicks the ass of our previous instancing code
for the love of god
please make this a verification test
I'm literally begging you
a what
you make a unit test
and the unit test does 4 things:
- setup the scene
- render one frame
- dump everything to bytes in .png format
- call Verify.Accept(yourBytes)
and that's it
verification test
you win
then do that, but parameterize it to do it for all backends
and you have more testing then 99% of graphics dev
what unit testing framework
i think we use Xunit in the main Furball repo
XUnit + Verify.Xunit
cool
that should actually be really easy to do tbh
it really should
and it helps sooooo much
and with verification tests you can even still look at the file
and visually tell whether everything is good
just then it's stored and you don't think about it
ill do that once i get veldrid and dx11 working, as then ill probably have a better idea of a good test scene that tests all aspects
<3
TIL I learned about https://registry.khronos.org/OpenGL/extensions/EXT/WGL_EXT_swap_control.txt
gl 1.2 :^)
What does verify.Accept do?
Ahh, that seems a bit finicky IMO
it just writes to a file, and then you rename the file to .accepted.*
I use a rider plugin to do the rename
Acceptance testing is usually intended to just verify something is still working, so those files rarely change
So the finicky / work aspect are tiny compared to the added confidence that something still works
one thing which will throw a wrench into the plan is that the png encoder in ImageSharp will likely change over time, and also its very very likely that different GPUs will be just a few pixels off when it comes to blending and stuff on different APIs
even if it visually is the exact same it might be different when pixel peeping
well in that case you can just make it accept a +-10% image difference or something
iirc image sharp even provides that?
oh
in that case its easy
though then you can't use Verify.XUnit
easy enough to do yourself though
yea
even if imagesharp doesnt have it then i can just write it myself
... i don't think you need to worry about PNG
because it's a lossless format 🙃
what i mean is comparing the raw bytes
but yes, blending on different gpus
you should not be comparing raw bytes but colors :
yeye
but kai said raw bytes
not colours
so thats why i mentioned encoding differences
maybe use bitmaps then
maybe
which won't be good for git history
but i think itd just be smarter to save it as png, then compare colour by colour
yeah even monogame does that
i think they have a repository submodule for test images
so it doesn't clog the main repo
i think id be fine with a few pngs in the repo that change occiasionally
it will slow down a lot of git operations
so just use a submodule
o oki
wut
how will it slow down git operations @techpizza ?
probably cus its binary files
that doesn't really inherently slow down git operations
I mean, don't render at like 12k obviously
the pack files grow super large
Only if the binary file is pretty big and changes often
Verification tests change never / very rarely & have small files
¯\_(ツ)_/¯
thankfully this is a thing so its easy for me to set the attribute location without the layout qualifier
i think i know how i did this
shaders successfully ported to GLSL 110
now time to test under mesa gl 2.0 with GLSL 110
huh thats odd https://i.beyleyisnot.moe/ExYrq3c.png
{kind=link}
oh so the nvidia compiler LIED to me https://i.beyleyisnot.moe/jdti2cE.png
{kind=link}
{kind=link}
can i do a reinterpret cast in GLSL :^)
im trying to abuse VertexAttribPointer but its not working
the one time i want vertexattribpointer to autocast to float
it wont let me
IT WORKED YES
this is such hard abuse of what it was probably meant for
but it works
{kind=link}
@furball.vixie is it good if i create one set of Shaders then reuse that for all the renderers? currently we create a new shader pair for every renderer
which can get a little slow when we are doing a lot of renderers
and is very memory intensive
that sounds like a very good idea
both for speed and vram sake
cool
will do
although idk how much shaders take up in vram
probably not much, but when we load up on Renderers, it will add up
and any improvement is good improvement in my book
when we're targetting machines that could potentially have max 128mb VRAM any save is good
ye
oo i can save 1 gl call per renderer draw
if i set the projection matrix only when it changes, then bam ive just saved a single gl call per draw
insane
hey look ok i get excited about this stuff its fun to optimize like this
i like looking at code and using pure brain muscle to save microseconds
i know im trying to play along
i know i know im joking
the double juke
{kind=link}
{kind=link}
i just realized
we can actually share shaders between multiple backends now
cus they are nearly identical
its something ill look into
spirv cant target version 100 or 110
nothing a little search&replace cant fix
nor can it target d3d9 if i recall rorrectly
only 9.3
well yeah but it would be nice to at least have 2 backends sharing shader code
just makes upkeeping them that little bit less painful
i think getting this to work would be more painful than having them seperate
well yeah but itd be fun and we'd get any optimizations the Spir-V compiler does
so approximately 0 because its going to GLSL and HLSL down the line anyway
btw how did you compile the Vulkan shaders, id like to work on that a little bit since i have the time
when did i compile vulkan shaders

here
i dont remember ever compiling vulkan shaders

eh whatever ill just write a script to do it
okay no i do remember
cuz the fucking compiler is an actual ape head and cant deal with utf8
and the byte order mark made compilation fail every single time
oh you can disable the BOM in rider, ive had to do that with the OpenGL backend too
i shouldnt have to
but cuz the compiler is stupid sure i guess
i did notice that at the bottom
it also took me solid 20 minutes to figure out why it didnt want to work
it involved me going into a hex editor to see what the hell is happening
and googling the bytes i thought 'what are those'
google then correctly told me it was the byte order mark in utf8
rip
there we go
simple script
you can even run the script through rider